
The first thing you notice as a senior engineer working with AI coding tools is that the bottleneck isn't the AI. The model writes code fast. The PR shows up. And then your afternoon disappears into reviewing it, finding the four things it got subtly wrong, explaining why, watching it try again, and shipping something that was supposed to take an hour.
You start to do the math on where your time actually goes. Most of it isn't writing code. It's reviewing AI output, unblocking teammates whose AI got stuck, and rerunning prompts because the model lost the plot somewhere in a 90 minute session.
The teams that have figured this out aren't using bigger models. They're using the right model for each phase, running tasks in parallel, and writing the spec down so the AI, their teammates, and their future selves all agree on what is being built before any code gets generated.
This post walks through the workflow that senior engineers and tech leads have converged on, with the operational details that make it stick on a real team. For a broader introduction to multi-model workflows, see One AI Model for Everything Is Costing You.
The actual problem is attention, not tokens
Token cost gets the headlines. Calendar cost is the one that hurts.
A typical senior engineer's day involves five or six meetings, two or three code reviews, one or two production incidents, and whatever feature work they can fit in the gaps. AI coding tools were supposed to give time back. For a lot of people they haven't, because the workflow still requires the senior engineer to be the model's pair programmer. Every prompt is a context switch. Every review is a recovery from a context switch.
The fix isn't to prompt better. It's to structure work so the AI can run without you in the loop for stretches long enough that you can do something else.
| Where senior time leaks | Why it happens | What changes with multi-model |
|---|---|---|
| Reviewing AI output | Same model wrote and reviewed the code | A different model catches different things, fewer cycles |
| Re-prompting after drift | Long sessions degrade context | Each phase runs in fresh context |
| Pair programming with the AI | No spec to hand off to | Plan once, the spec coordinates everything |
| Sequential task execution | One task at a time, watched constantly | Parallel worktrees, batch review later |
Andrej Karpathy described the failure mode that keeps senior engineers stuck in the loop:
The mistakes have changed a lot. They are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should.
@karpathy · January 2026
The wrong assumptions are the expensive part. Not the tokens. The hours.
Spec as contract: the move that changes everything
The single highest leverage thing a senior engineer can do with an AI coding workflow is spend ten minutes getting the spec right before any code is generated.
A frontier reasoning model writing a spec produces a document that pins down the architecture, the affected files, the edge cases, and the verification criteria. Once that document exists, every downstream actor (a fast implementation model, a different reviewer model, a junior teammate picking up the next ticket) reads from the same source of truth.
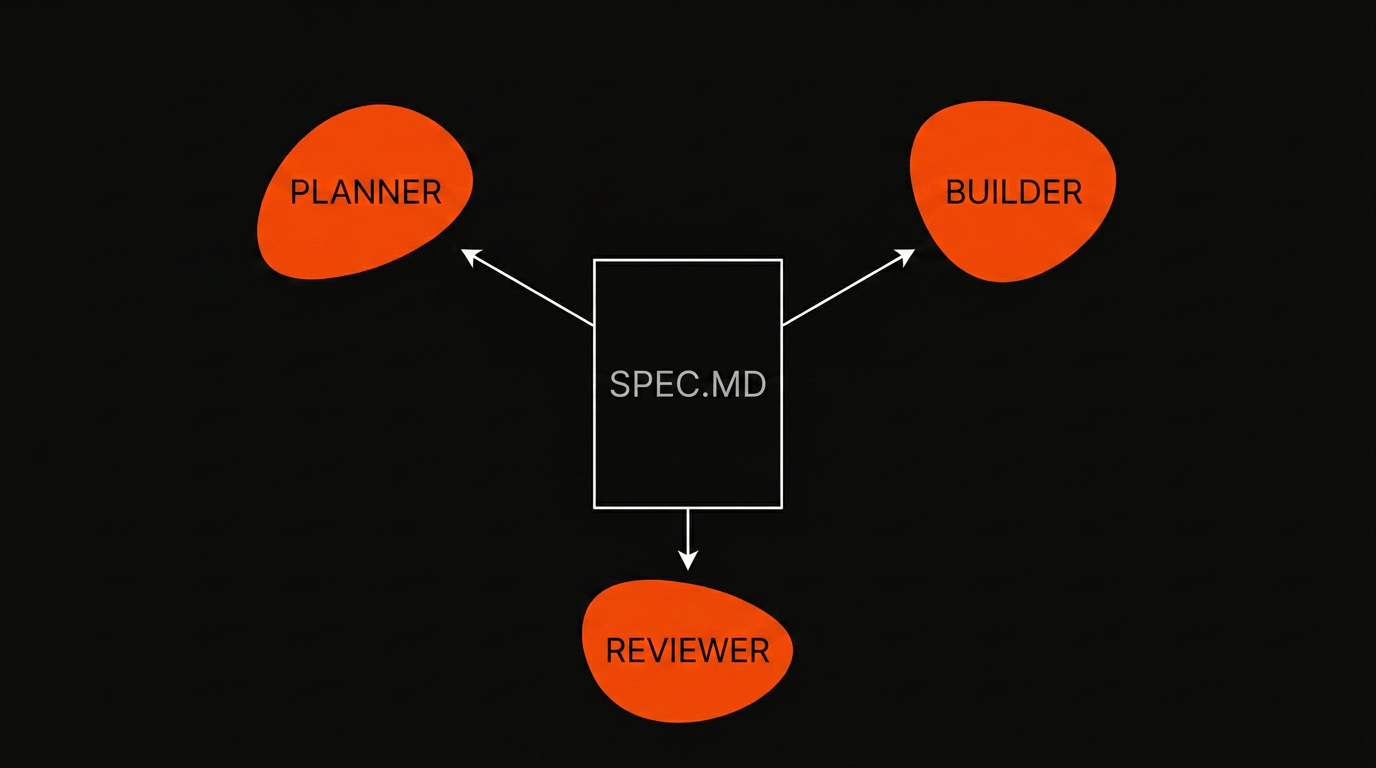
The mechanic is the part that matters. The spec is a file. It sits on disk. It gets committed. It survives the chat window closing. Once it exists, the implementer doesn't have to re-derive architecture from scratch. The reviewer has something concrete to verify against. A teammate picking up the next ticket has the same reference you did.
For a senior engineer, the spec is also the artifact you actually review. You're not reviewing 800 lines of generated code line by line. You're reviewing a one page spec that took ten minutes to read, and trusting that the implementation matches it because the reviewer model verified it did.
That changes the review loop from "read every diff carefully" to "spot check the spec, glance at the diff, run the tests."
Worktree parallelism: getting the afternoon back
The other half of the workflow is running multiple tasks at once.
Zenflow gives each task its own Git worktree at .zenflow/worktrees/{task_id}. Different tasks live in entirely separate directories. There's no branch contention, no half written code on your main checkout, no mental tax from juggling state across tasks.
.zenflow/worktrees/
├── task-auth/ ← planner writing the spec for OAuth refresh tokens
├── task-billing/ ← builder implementing the invoice export endpoint
└── task-search/ ← reviewer auditing the new search index changesWhat this enables, in practice, is the workflow Harper Reed was explicitly asking for at the end of his 2025 post on LLM coding workflows:
I have spent years coding by myself, years coding as a pair, and years coding in a team. It is always better with people. These workflows are not easy to use as a team. The bots collide, the merges are horrific, the context complicated. I really want someone to solve this problem in a way that makes coding with an LLM a multiplayer game.
Harper Reed · February 2025
Multi-Model Workflow at a Glance
| Phase | Model Family | Artifact | Typical Duration |
|---|---|---|---|
| Planning | Frontier reasoning model | spec.md |
5–15 minutes |
| Security Review (optional) | Specialist reasoning model | security-review.md |
5–10 minutes |
| Implementation | Fast coding model | Source code commits | 15–90 minutes |
| Automated Testing | Testing agent | Test results and logs | 5–20 minutes |
| Cross-Model Review | Different reviewer model family | review.md |
5–15 minutes |
| Security Audit (optional) | Security-focused reviewer | security-audit.md |
5–15 minutes |
| Final Human Review | Senior engineer or tech lead | Approval or feedback | 5–20 minutes |
| Merge & Deployment | CI/CD pipeline | Pull request and deployment artifacts | Varies by workflow |
A worked example: shipping three tasks in one day
Concretely, here is how a senior engineer can move three tickets through to merge between standup and end of day. Three is a useful number because it stretches the workflow without overwhelming a single reviewer.
The three tickets in this example:
- Ticket A: Add OAuth refresh token rotation to the auth service
- Ticket B: Build an invoice CSV export endpoint with pagination
- Ticket C: Add a date range filter to the search index API
Each ticket has different complexity. Ticket A is the riskiest (security implications). Ticket B is straightforward. Ticket C is small. They don't depend on each other.
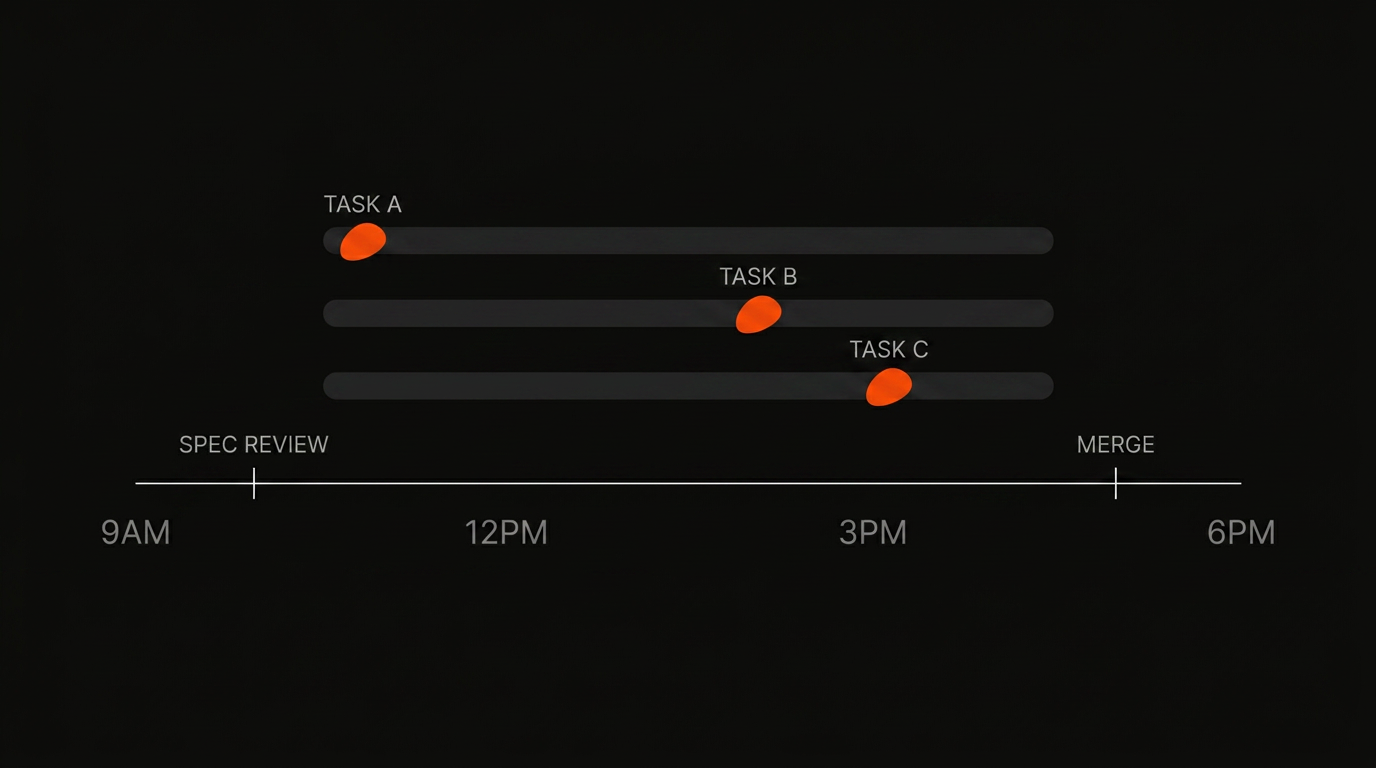
8:55 am. Before standup, create three tasks in Zenflow with the Multi-model workflow. Paste the ticket description into each. Each task gets a planner running on a frontier reasoning model. Each task gets its own worktree.
9:00 to 9:20 am. Standup. Talk about other things.
9:20 am. All three specs are sitting in their worktrees. spec.md in each.
9:20 to 9:50 am. Read all three specs. Tighten what needs tightening. For Ticket A, the spec should explicitly call out token rotation edge cases (concurrent refresh, replay attacks). For Ticket B, confirm the pagination contract matches the rest of the API. For Ticket C, the spec is small enough to approve as-is. This thirty minutes is the only deep-focus block the day requires.
9:50 am. Approve all three. Builders start on a fast model in each worktree.
10:00 am to 1:00 pm. Design review, 1:1, lunch. Three builders are running in the background. Each one auto-commits as it completes plan steps.
1:00 pm. Check in. Ticket B and Ticket C are done. Ticket A has a question: the builder ran into ambiguity about whether to invalidate the old token immediately or grace-period it. The spec didn't fully resolve this. Answer in one sentence. Builder continues.
1:10 to 4:00 pm. More meetings. Cross-model reviewers kick in as each builder finishes.
4:00 pm. Reviewer artifacts are ready. Open each review.md:
- Ticket A review: One genuine finding (the spec didn't cover token reuse detection). Worth a second pass. Push back to the implementer with a one-line correction.
- Ticket B review: Clean. Merge.
- Ticket C review: One stylistic note. Ignore. Merge.
5:00 pm. Ticket A's second pass is in. Reviewer is happy. Merge.
Three tickets shipped. Deep focus time: about 40 minutes (spec review plus the second-pass decision). The rest of the day was attended to other work. This is the shape that's hard to get to with a single agent watched in real time.
Cross-model review and the trust problem
The reason senior engineers end up doing line by line review of AI output is that they don't trust same model review. They're right not to.
When a model reviews code it wrote, it retraces its own reasoning. The wrong assumption it made during implementation is the wrong assumption it carries into review. Confirmation bias, basically: the model anchors to its own logic and fails to detect errors it introduced.
Different model families have different blind spots, different training data, different priors. When a reviewer model from a different family checks the diff, it brings structurally different assumptions. And when three reviewers from three different families converge on the same finding, that convergence is real signal, not noise.
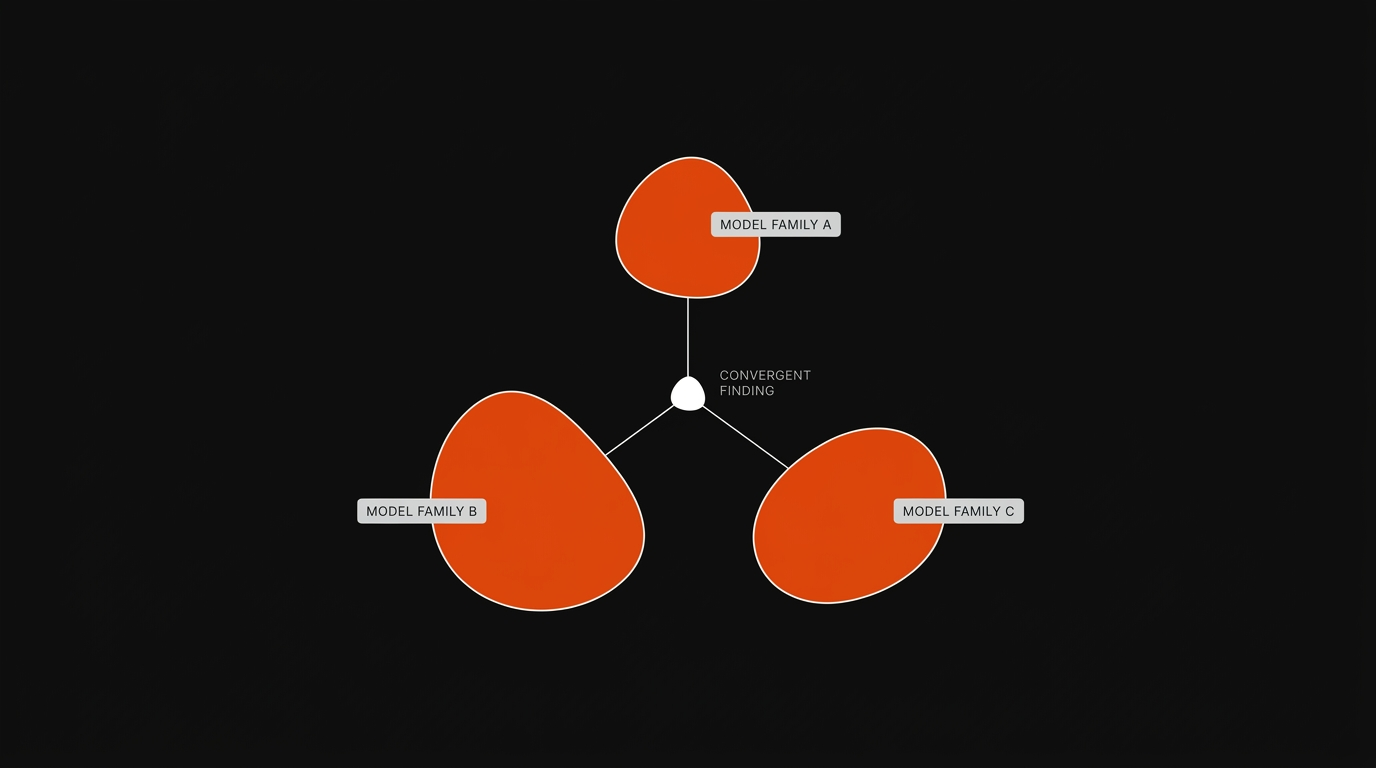
For a senior engineer this is what makes the workflow possible. You're not skipping review. You're letting cross model review do the first pass so your review can be the strategic one. You read what's flagged, you spot check what isn't, and you ship.
What goes wrong (and how to recover)
The day-in-the-life above is the good version. Here is what actually breaks, and what you do about it.
The spec is wrong. The planner makes a bad architectural call (chose the wrong abstraction, missed a constraint). You catch this during spec review. Reject the spec, give the planner a one-line correction, and rerun. Spec review is the only place this is cheap to catch. If you let a bad spec through, the builder will faithfully implement the wrong thing.
The builder takes a wrong turn. The spec didn't cover an edge case and the builder picked an interpretation you wouldn't have. You catch this in the review artifact, not in the diff. Push back with a one-line clarification and let it re-run. Don't manually patch unless the change is trivial.
The reviewer is too noisy. Some reviewers flag stylistic concerns or speculative regressions. You learn to skim the review and weight findings by your team's standards. A few tasks in, you'll know which signal to trust.
Two tasks touch the same file. Worktrees prevent in-flight conflicts but merges still need ordering. Set up your CI to require sequential merges on overlapping paths. Run the second task's tests against the first one's merge target before approving.
You picked the wrong model for a phase. The reviewer model is too lenient, or the builder is too slow. Adjust the preset and rerun the task. The investment in a good preset library pays back across every future task.
Standardizing it for your team
The personal productivity story is real. The team story is what makes a tech lead's life easier.
A custom workflow template in Zenflow is a markdown file that codifies which model runs which phase, what artifacts get produced, and what review rubric applies. Once you've found a workflow that works for your team's auth tasks, your team's migration tasks, your team's bug fixes, you save it as a template and every teammate uses the same shape.
# Auth Feature Workflow
## Configuration
- **Artifacts Path**: {@artifacts_path} → `.zenflow/worktrees/{task_id}`
---
### [ ] Step: Security Architecture Review
<!-- agent: planner -->
Analyze the feature for security implications. Document threat model,
attack vectors, and mitigations in `{@artifacts_path}/security-review.md`.
### [ ] Step: Implementation
<!-- agent: builder -->
Implement following `{@artifacts_path}/spec.md` and security review.
Include all mitigations from the security review.
### [ ] Step: Security Audit
<!-- agent: reviewer -->
Audit the implementation against the security review.
Check for OWASP Top 10 vulnerabilities.
Record findings in `{@artifacts_path}/security-audit.md`.What this gives the team:
- A junior engineer running an auth task gets the same security review step a senior engineer would have added manually
- The diff that lands in PR review already has a consolidated review artifact attached
- New teammates onboard onto the workflow, not onto tribal knowledge
- The senior engineer's judgment is captured once, in a file, instead of repeated in every pairing session
This is the part that turns multi-model from a personal hack into a team standard.
Frequently asked questions
What is a multi-model AI workflow for senior engineers?
A multi-model workflow assigns different AI models to different phases of a coding task: a frontier reasoning model for planning, a fast model for implementation, a different model for review. For senior engineers, the value is structural: spec once, run multiple builders in parallel, batch-review the diffs, stop being a full-time pair programmer with the AI.
How does spec-as-contract work in practice?
The planner writes a spec to disk. The implementer reads it and writes code against it. The reviewer reads it and verifies the code matches. You review the spec, not the diff line by line.
What are Git worktrees and why do they matter?
A worktree is a separate working directory tied to the same repo but checked out to a different branch. Zenflow gives each task its own worktree under .zenflow/worktrees/{task_id}, so multiple AI tasks run simultaneously without branch contention.
How do I roll out a multi-model workflow to my team?
Codify recurring patterns as Zenflow custom workflow templates. Each template specifies models per phase, artifacts produced, and review criteria. Every teammate using the template gets the same shape.
What if I'm not a senior engineer?
The workflow still applies, but you get more value from the structured spec and the review artifact (they substitute for the senior engineer's instinct on what to check). Start with the default Multi-model workflow in Zenflow before customizing.