
Disclaimer:
This paper focuses exclusively on self-hosting LLMs on servers equipped with industrial-grade GPUs (either owned or rented). This paper does not cover scenarios involving deployment of small- to medium-scale models directly on consumer laptops, desktops, or mobile devices.
In this document, we discuss LLMs in the context of programming-related tasks, with a primary focus on the GLM-4.5-FP8 model.
When referring to benchmarks, we specifically mean one of two categories:
- Inference performance tests – e.g., tokens per second, LLM request end-to-end latency, or task completion time.
- Model quality benchmarks – e.g., the percentage of tasks successfully solved on a given benchmark dataset.
Self-hosting Large Language Models (LLMs) means running inference (and optionally fine-tuning) on infrastructure you control—on-premises, or in a private cloud. This approach can deliver strong privacy guarantees and operational control, but it also shifts cost, reliability, and performance risks onto your team. Below, we outline the principal advantages and trade-offs to set context for the rest of the paper.
Key Advantages
- Data privacy & closed environments. Keep sensitive data in air-gapped or regulated networks, meet strict compliance needs, and avoid third-party data processing.
- Greater control over stability and uptime. Your SLAs are not coupled to external providers’ outages or traffic shaping (cf. periodic incidents visible on vendor status pages). You decide maintenance windows and failover plans.
- No vendor rate limits. Throughput is bounded by your own capacity planning, not an API’s per-minute/ per-day quotas. You can optimize batching and queueing policies to meet internal SLOs.
Key Trade-offs and Challenges
- Capital and utilization risk. You pre-pay for hardware, facilities, and power; costs accrue even when models are idle—effectively paying by wall-clock time rather than by token. Achieving high utilization is critical to TCO.
- Harder to scale elastically. Unlike token-based cloud consumption, scaling up requires procurement lead times, cluster integration, and capacity planning; scaling down still leaves you with fixed assets.
- Operational expertise required. You’ll need personnel to monitor load and reliability (SRE/MLOps) and, if you pursue performance optimization, engineers familiar with inference runtimes (e.g., vLLM, SGLang, llama.cpp), quantization, KV-cache policies, parallelism strategies, and observability.
- Model feature gaps. Open-weight models may lag behind closed-source offerings in benchmarks (e.g., reasoning, coding, long-context handling) and often lack multimodal capabilities such as image processing. This can limit parity with cutting-edge API providers.
- Missing ecosystem services. Cloud vendors typically bundle auxiliary APIs—e.g., file storage APIs for document handling, embedding/search services, or RAG orchestration tools. Self-hosting requires replicating or integrating such functionality with third-party or in-house solutions.
Deployment model choices
- Owning hardware: purchasing and operating your own GPU servers on-premises or in colocated data centers and manually deploying/optimizing inference runtimes.
- Cloud hardware rental: leasing GPU instances in IaaS providers (AWS, GCP, Azure, etc.) and manually deploying/optimizing inference runtimes.
- On-demand managed deployments: renting dedicated GPUs for models via services such as Fireworks on-demand deployments, where you avoid low-level inference setup but still retain model control and isolation.
Takeaway: self-hosting is most compelling when data control, predictable latency, or customization outweigh the convenience and elasticity of managed APIs. The following sections detail hardware constraints, local-inference options, and benchmark evidence to inform that decision.
Models
As a next step, we briefly compare the currently available open-weight models with their closed-source counterparts
|
Model Name |
Parameters |
Pricing (per 1M tokens) |
Image Support |
SWE-Bench-Verified Score |
Context Window |
Release / Announce Date |
|
Claude Sonnet 4 |
Not publicly disclosed |
Input $3; Input cache: $0.3, Output $15 |
Yes |
53.0% [no-agent] / 72.4 % |
200K |
May 2025 |
|
GLM-4.5-FP8 |
355B total / 32B active |
No (Yes with new version GLM-4.5V) |
50.9% [no-agent]/ 64.2% |
128K [8xB200] / 65K [4xB200] |
July 2025 |
According to our internal analysis, the money token distribution is approximately as follows:
- input / cache write = ~0.4 of total $
- cache read = ~0.4 of total $
- output = ~0.2
GPU Capabilities Overview
|
GPU Model |
FP8 Support |
FP16 Support |
VRAM Capacity (per card) |
|
NVIDIA A100 |
No |
Yes |
40 GB or 80 GB HBM2e |
|
NVIDIA H100 |
Yes (Tensor Cores) |
Yes |
80 GB HBM3 |
|
NVIDIA B200 |
Yes (improved FP8, Tensor Cores) |
Yes |
192 GB HBM3e |
In this document, we focus on deploying the GLM-4.5-FP8 model, which means that the A100 GPU is not suitable for our setup.
Based on preliminary estimates using the apxml VRAM calculator, deploying GLM-4.5-FP8 would require approximately ~600 GB of VRAM.
In our experiments, we used 4xB200+ARM CPU+Ubuntu 24.04.1 LTS.
Inference
Engines
Efficient inference is at the core of self-hosting LLMs. The choice of runtime directly affects throughput, latency, and hardware utilization. Below we describe two widely adopted engines designed for large-scale inference.
vLLM [v0.10.0, commit: 309c1bb]
- vLLM is an open-source inference engine optimized for high-throughput LLM serving. Its core innovation is the PagedAttention mechanism, which manages the key–value (KV) cache in a memory-efficient manner, enabling very long context windows without prohibitive memory overhead.
SGLang [v0.4.10]
- SGLang is a newer open-source inference framework designed to go beyond traditional token streaming. It emphasizes structured generation and function calling, targeting agentic and tool-augmented LLM applications
Deployment
Because inference engines must run across diverse hardware environments, several factors—operating system, CUDA version, GPU type, and CPU architecture (x86 vs. ARM)—directly affect compatibility.
For both vLLM and SGLang, we recommend starting with the official Docker containers, which are generally available for common setups. Containers simplify dependency management and provide a stable baseline.
However, even with official builds, issues may still arise (see, for example, known deployment issues reported by the community). This is largely due to the fact that vLLM and SGLang are not monolithic binaries but frameworks that integrate multiple external components—custom CUDA kernels, inter-process communication libraries, distributed runtimes, etc. These dependencies may be missing or incorrectly compiled for a given hardware and OS combination.
In such cases, you may need to manually rebuild certain components from source. In practice, this troubleshooting and rebuilding process often takes several days, depending on hardware complexity and team experience.
For example, for vLLM we used this docker files: ARM, X86_64
Performance test GLM-4.5 on production data
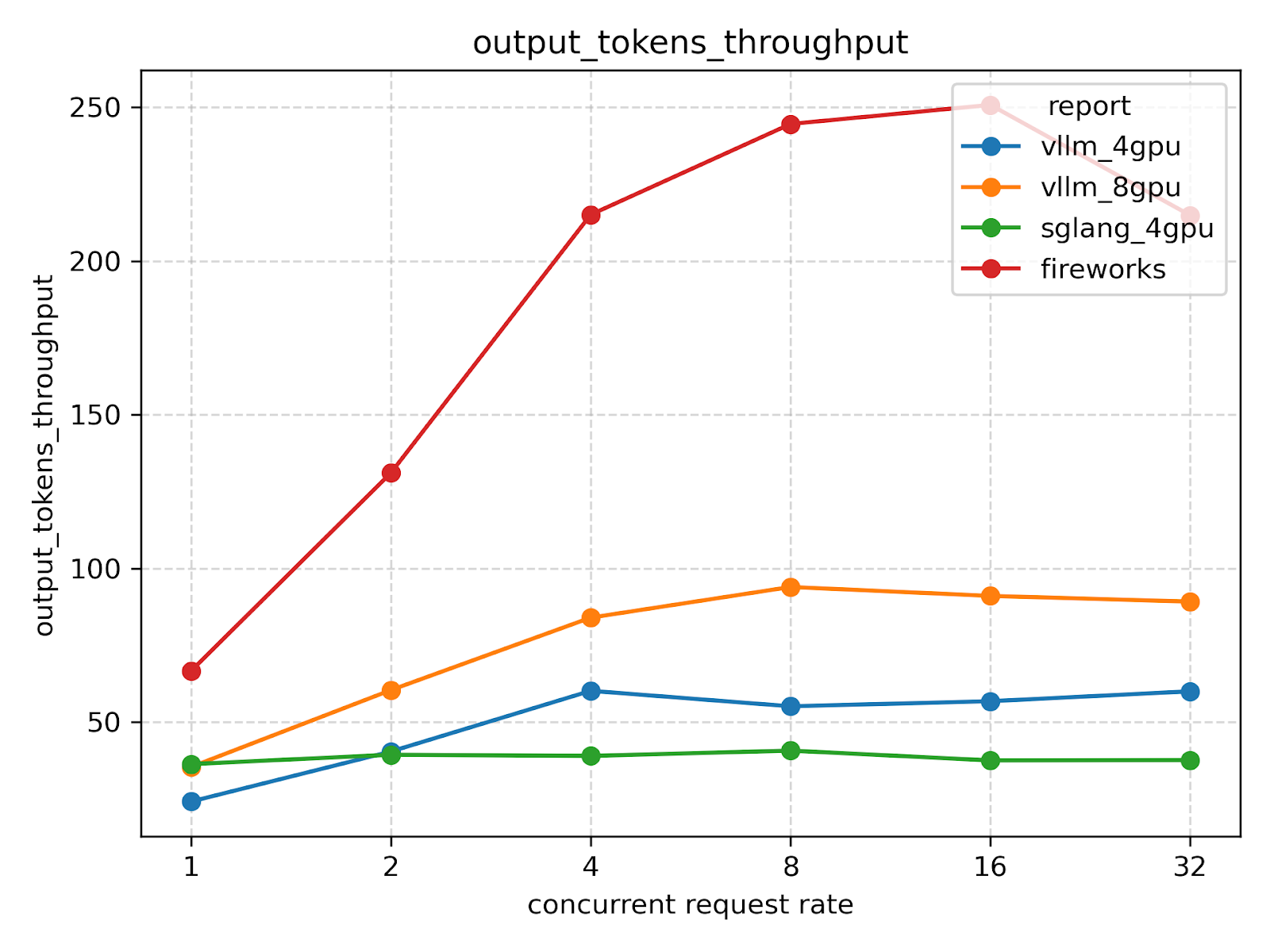
To evaluate inference performance under realistic conditions, we randomly sampled N = 97 fragments of real-life software engineering trajectories. Each fragment contained between 1 and 25 LLM calls, potentially including tool invocations. We then re-executed these trajectories on a setup combining vLLM with the GLM-4.5-FP8 model, measuring latency and throughput across the entire workload.
In total, there were approximately ~200 requests to the LLM. (<65K pre request)
We used the Fireworks API as the baseline.
Tokens in dataset
These statistics will vary slightly from experiment to experiment due to timeout errors on some requests under high request rates.
Tokens per request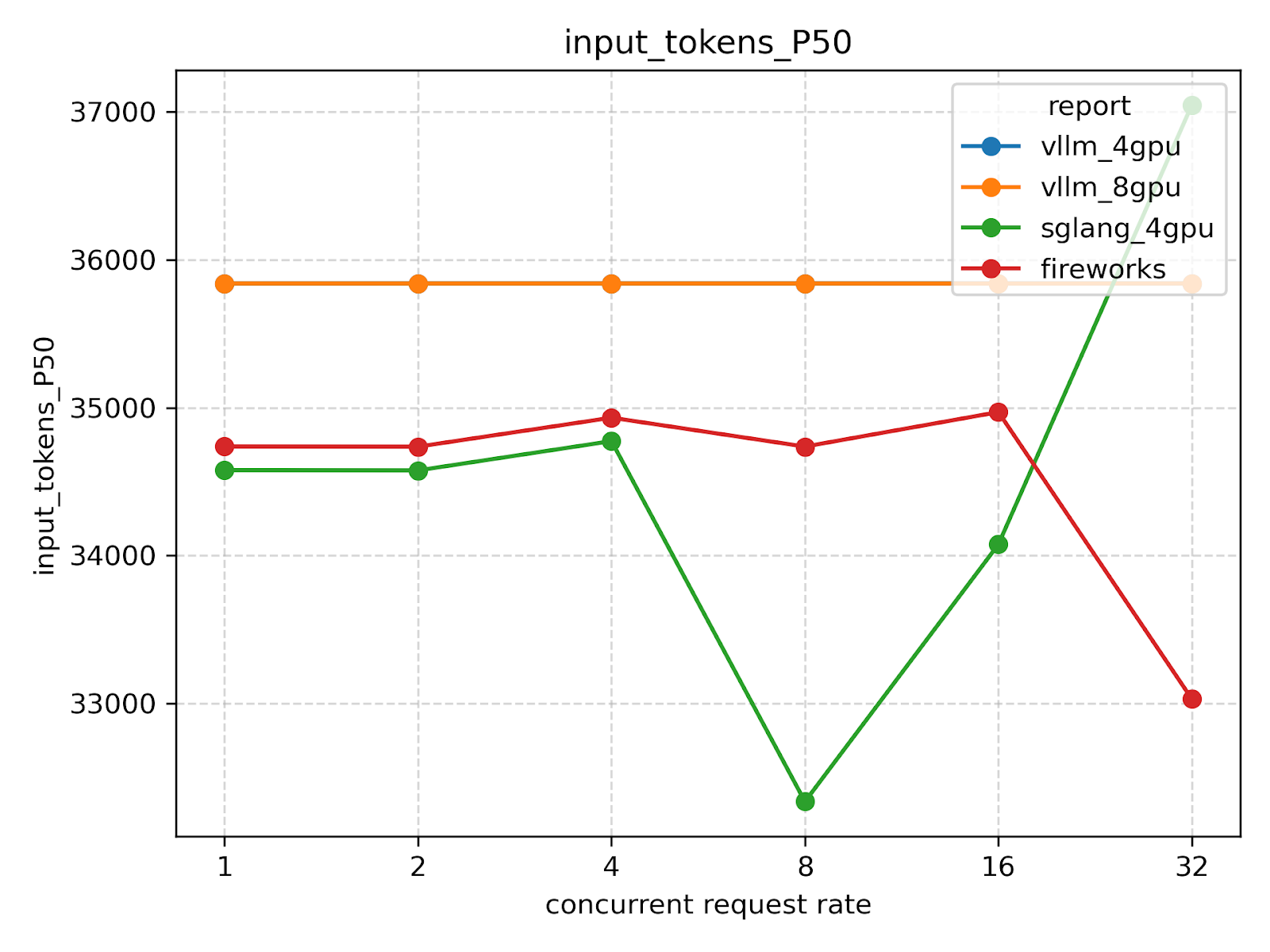
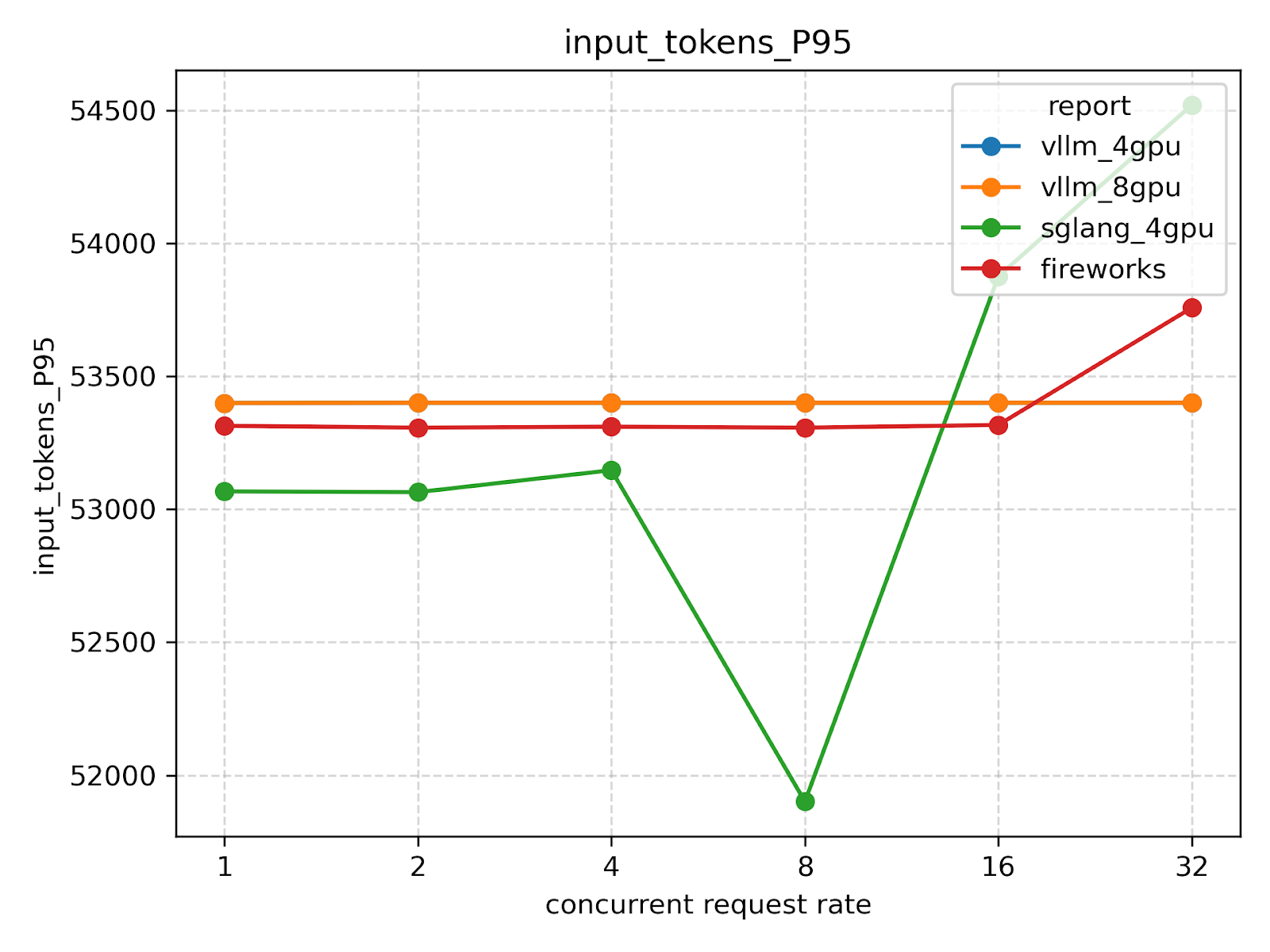
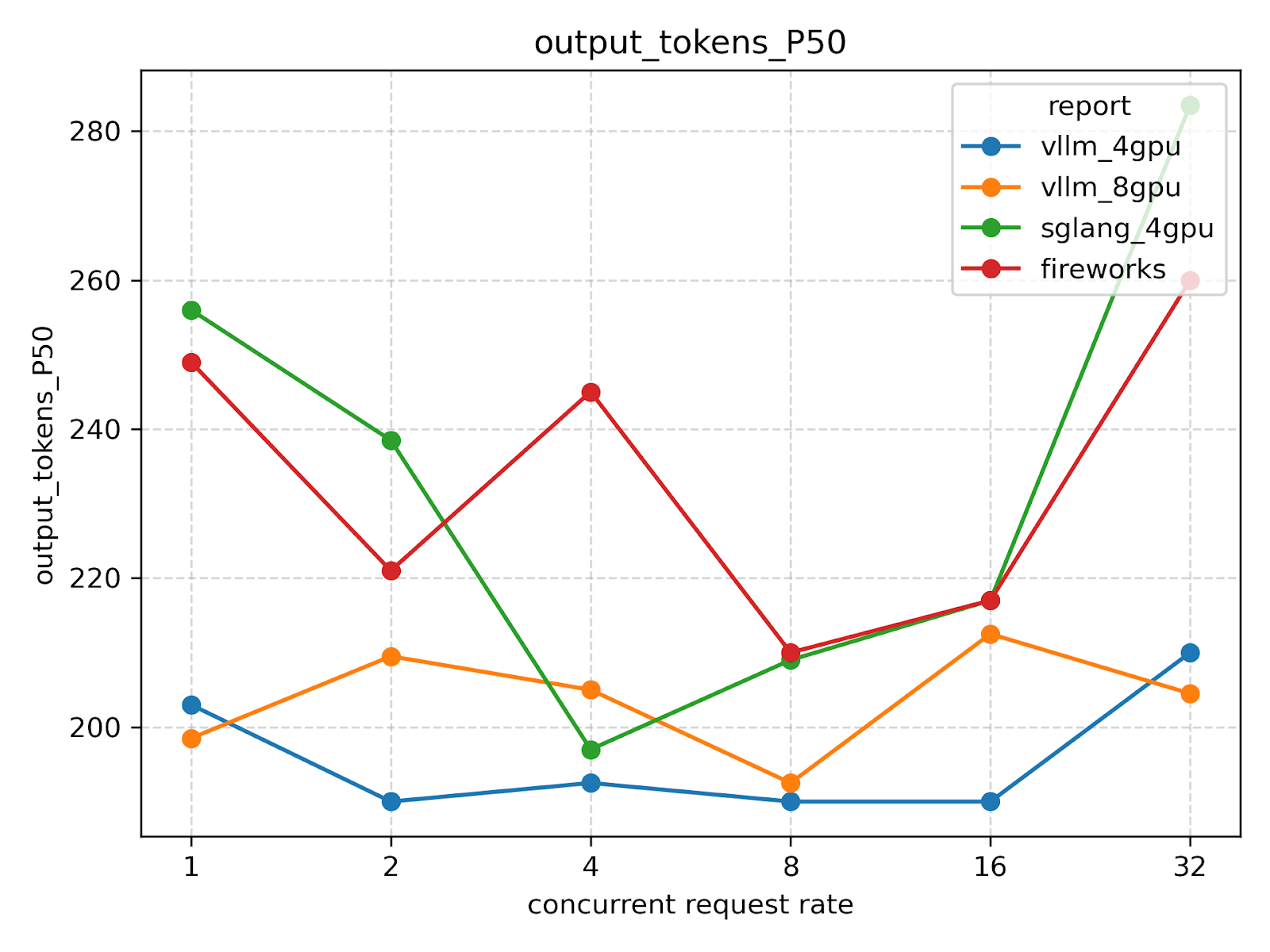
 Total tokens
Total tokens


Duration end-to-end per request


Total duration

Input/Output throughput (tok/sec)
 SWE-Bench-Verified
SWE-Bench-Verified
To evaluate task execution speed under varying levels of concurrency, we launched N parallel agents solving the SWE-Bench-Verified (medium_hard_50 subset). As a baseline for comparison, we used the Fireworks API.
Tokens in medium_hard_50 [GLM-4.5]:
This is the statistics on output tokens per LLM request. In other words, we simply take all LLM calls made within a single experiment and compute P50 and P95.
The statistics on input/output tokens will vary from experiment to experiment, but this is due to overall variance and is not related to the number of concurrently running agents.
|
Type |
P50 |
P95 |
|
Input tokens |
33K |
~50K |
|
Output tokens |
78 |
900 |


If we look at the output tokens while running one task, it would look something like this:
Result of running on GLM-4.5-FP8 on our experimental agent
|
Provider |
Tasks Passed |
Concurrent agents |
P50 task [successful and unsuccessful] duration |
P95 request [successful and unsuccessful] duration |
|
Fireworks API |
39 |
2 |
202 sec |
2.13 sec |
|
VLLM |
32 |
2 |
450 sec |
3.55 sec |
|
Fireworks API |
33 |
4 |
257 sec |
2.21 sec |
|
VLLM |
33 |
4 |
509 sec |
4.41sec |
|
Fireworks API |
35 |
8 |
258 sec |
2.34 sec |
|
VLLM |
37 |
8 |
587 sec |
4.55 sec |
|
Fireworks API |
30 |
16 |
318 sec |
2.67 sec |
|
VLLM |
34 |
16 |
696 sec |
5.36 sec |
|
VLLM |
29 |
32 |
901 sec |
6.66 sec |
Comparison of the Quality of Open-Weight and Closed Models
The reported numbers are based on internal testing under varying agent configurations, and should therefore be considered approximate. Nevertheless, we believe they provide a useful basis for comparing the capabilities of open-weight models against closed frontier models.
SWE-bench-verified / medium_hard_50
|
Model Name |
Tasks Passed |
|
glm-4.5 |
~30 |
|
qwen3-coder-480b |
~30 |
|
gemini-2.5-pro |
~27 |
|
claude-sonnet-3.7 |
~30 |
|
claude-sonnet-4 |
~37 |
|
claude-opus-4-1 |
~40 |
|
gpt-5 (high reasoning) |
~40 |
Internal benchmark [52 tasks]
|
Model Name |
Tasks Passed |
|
glm-4.5 |
~4 |
|
kimi k2 |
~3 |
|
qwen3-coder-480b |
~5 |
|
gemini-2.5-pro |
~5 |
|
claude-sonnet-4 |
~10 |
|
gpt-5 (high reasoning) |
~12 |
|
gpt-5-medium |
~8 |
|
grok-code-fast-1 |
~9 |
|
open4.1 |
~5 |
Conclusion
How many concurrent users can a 4×B200 setup support?
There is no single definitive number—capacity depends heavily on workload characteristics, prompt/response lengths, concurrency patterns, and latency requirements. Based on our experiments and rough estimation, a 4×B200 cluster can realistically sustain around 8–16 concurrent active users while keeping task completion times within acceptable bounds
How far behind are open-weight models compared to closed frontier models?
One major limitation is that GLM-4.5 does not support images, which makes it less suitable for tasks involving front-end development or multimodal reasoning (although GLM-4.5V adds vision support, it is a smaller model).
On SWE-Bench-Verified (focused exclusively on Python tasks), GLM-4.5 achieves results broadly comparable to Claude Sonnet-4. However, in our internal benchmarks—which include a wider variety of programming tasks—we observe a noticeable performance gap relative to Sonnet-4, which remains the most widely adopted programming-oriented model at the time of writing.
It is also worth noting that on the 4×B200 setup we used a 65K context window for GLM-4.5, which is clearly more limited compared to the 200K tokens available in Sonnet-4
How difficult is it to deploy inference engines?
The exact time depends on your expertise in this area, your hardware setup, driver/CUDA compatibility, and whether additional components need to be rebuilt from source
Appendix
SGLang benchmark params
backend="sglang-oai-chat",
base_url=base_url,
host=None,
port=None,
model=model,
tokenizer=LOCAL_TOKENIZER_DIR,
dataset_name="random",
dataset_path="",
dataset_format=None,
num_prompts=400,
random_input_len=749,
random_output_len=181,
random_range_ratio=0.3,
profile="poisson",
request_rate=request_rate,
max_concurrency=512,
warmup_requests=5,
disable_stream=False,
output_file=f"~/bench.jsonl",
output_details=True,
disable_tqdm=False,
seed=int(time.time()),
tokenize_prompt=False,
apply_chat_template=False,
pd_separated=False,
flush_cache=False,
lora_name=None,
tokenizer_file=None,
sharegpt_output_len=None,
sharegpt_context_len=None,
prompt_suffix="",
disable_ignore_eos=False
Medium_hard_50 subset
{
"astropy__astropy-12907",
"astropy__astropy-14369",
"astropy__astropy-14995",
"astropy__astropy-7671",
"astropy__astropy-8707",
"django__django-13810",
"django__django-14315",
"django__django-15467",
"django__django-16255",
"django__django-16662",
"matplotlib__matplotlib-20488",
"matplotlib__matplotlib-21568",
"matplotlib__matplotlib-24026",
"matplotlib__matplotlib-25479",
"matplotlib__matplotlib-25960",
"psf__requests-1142",
"psf__requests-1724",
"psf__requests-1921",
"psf__requests-5414",
"psf__requests-6028",
"pydata__xarray-4966",
"pydata__xarray-6744",
"pydata__xarray-6938",
"pydata__xarray-7229",
"pydata__xarray-7393",
"pylint-dev__pylint-4551",
"pylint-dev__pylint-4970",
"pylint-dev__pylint-6386",
"pylint-dev__pylint-7277",
"pylint-dev__pylint-8898",
"pytest-dev__pytest-10051",
"pytest-dev__pytest-10081",
"pytest-dev__pytest-10356",
"pytest-dev__pytest-7982",
"pytest-dev__pytest-8399",
"scikit-learn__scikit-learn-10844",
"scikit-learn__scikit-learn-10908",
"scikit-learn__scikit-learn-13142",
"scikit-learn__scikit-learn-25232",
"scikit-learn__scikit-learn-25747",
"sphinx-doc__sphinx-7910",
"sphinx-doc__sphinx-7985",
"sphinx-doc__sphinx-8459",
"sphinx-doc__sphinx-8721",
"sphinx-doc__sphinx-9673",
"sympy__sympy-11618",
"sympy__sympy-13372",
"sympy__sympy-15345",
"sympy__sympy-18211",
"sympy__sympy-23262",
}


