
With large language models (LLMs) quickly becoming an essential part of modern software development, recent research indicates that over half of senior developers (53%) believe these tools can already code more effectively than most humans. These models are used daily to debug tricky errors, generate cleaner functions, and review code, saving developers hours of work. But with new LLMs being released at a rapid pace, it’s not always easy to know which ones are worth adopting. That’s why we’ve created a list of the 6 best LLMs for coding that can help you code smarter, save time, and level up your productivity.

6 Best LLMs for Coding to Consider in 2026
Before we dive deeper into our top picks, here is what awaits you:
|
Model |
Best For |
Accuracy |
Reasoning |
Context Window |
Cost |
Ecosystem Support |
Open-Source Availability |
|
GPT-5 (OpenAI) |
Best Overall |
74.9% (SWE-bench) / 88% (Aider Polyglot) |
Multi-step reasoning, collaborative workflows |
400K tokens (272K input + 128K output) |
Free + Paid plans starting $20/mo |
Very strong (plugins, tools, dev integration) |
Closed |
|
Claude 4 Sonnet (Anthropic) |
Complex Debugging |
72.7% (SWE-bench Verified) |
Advanced debugging, planning, instruction following |
128K tokens |
Free + Paid plans starting $17/mo |
Growing ecosystem with tool integrations |
Closed |
|
Gemini 2.5 Pro (Google) |
Large Codebases & Full Stack |
SWE-bench Verified: ~63.8% (agentic coding); LiveCodeBench: ~70.4%; Aider Polyglot: ~74.0% |
Controlled reasoning (“Deep Think”), multi-step workflows |
1,000,000 tokens |
$1.25 per million input + $10 per million output |
Strong (Google tool & API integration) |
Closed |
|
DeepSeek V3.1 / R1 |
Best Value (Open-Source) |
Matches older OpenAI models, approaches Gemini in reasoning |
RL-tuned logic & self-reflection |
128K tokens |
Input: $0.07–0.56/M, Output: $1.68–2.19/M |
Medium (open-source adoption, developer flexibility) |
Open (MIT License) |
|
Llama 4 (Meta: Scout / Maverick) |
Open-Source (Large Context) |
Strong coding & reasoning performance in open model benchmarks |
Good step-by-step reasoning (less advanced than GPT-5/Claude) |
Up to 10M tokens (Scout) |
$0.15–0.50/M input, $0.50–0.85/M output |
Growing open-source ecosystem, developer tools |
Open weights |
|
Claude Sonnet 4.5 (Anthropic) |
Collaborative Debugging & Long-Context Tasks |
Estimated ~75–77% (SWE-bench class) |
Hybrid agentic reasoning, autonomous tool use & planning |
200K tokens |
$3/M input + $15/M output |
Expanding the Anthropic ecosystem with agentic toolchains |
Closed |
1. Best Overall: OpenAI’s GPT-5
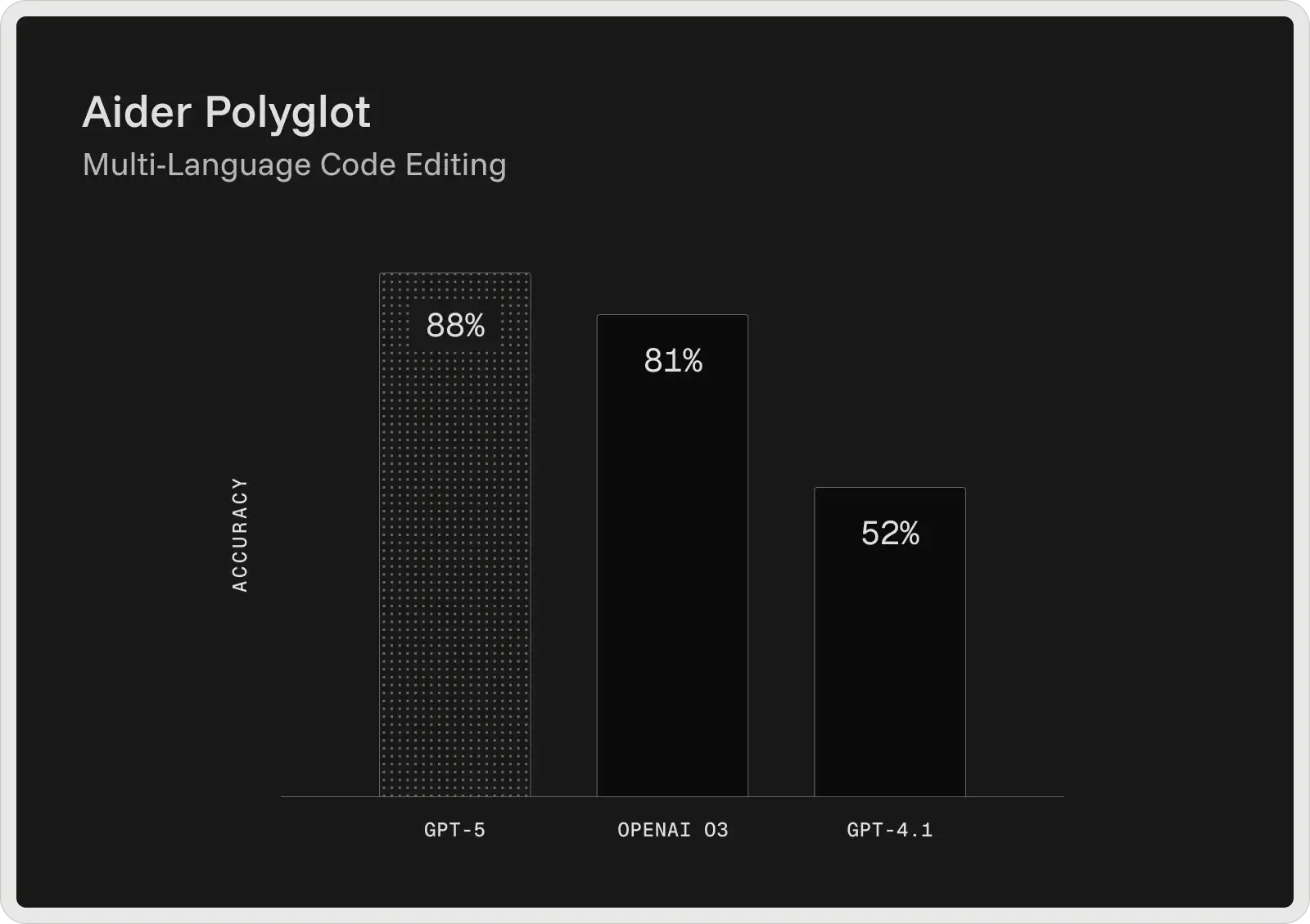
OpenAI’s GPT-5 is currently the strongest coding model in its lineup, delivering top results across widely used developer benchmarks. On the SWE-bench Verified, it achieves 74.9% accuracy, and on Aider Polyglot, it scores 88%, reducing error rates compared to earlier models, such as GPT-4.1 and o3. Designed as a collaborative coding assistant, GPT-5 can generate and edit code, fix bugs, and answer complex questions about large codebases with consistency.
It provides explanations before and between steps, follows detailed instructions reliably, and can run through multi-stage coding tasks without losing track of context. In internal testing, it was also favored for frontend development, where developers preferred its outputs to those of o3 about 70% of the time.
Key Capabilities:
- 400K-token context window – Handles 272K input + 128K output tokens, enabling repository-scale analysis, documentation ingestion, and multi-file reasoning.
- Advanced bug detection & debugging – Identifies deeply hidden issues in large codebases and provides validated fixes with clear reasoning.
- Tool integration & chaining – Calls external tools reliably, supporting sequential and parallel workflows with fewer failures.
- Instruction fidelity – Adheres closely to detailed developer prompts, even in multi-step or highly constrained tasks.
- Collaborative workflows – Shares plans, intermediate steps, and progress updates during long-running coding sessions.
- Long-context reasoning – Maintains coherence across large projects, preserving dependencies and logic over hundreds of thousands of tokens.
- Reliable content retrieval – Strong performance on long-context retrieval benchmarks (e.g., OpenAI-MRCR, BrowseComp), allowing it to locate and use information buried in very large inputs.
Pros and Cons:
🟢 Pros:
- Handles longer coding tasks and large codebases more effectively.
- Follows detailed instructions with higher accuracy.
- Catches subtle bugs that other models often miss.
- Produces cleaner, less “hallucinated” responses in some cases.
🔴 Cons:
- Struggles to fully implement complex, multi-step plans.
- Sometimes hallucinates or leaves code incomplete.
- Slower response speed and inconsistent output quality.
- Generated code can be overconfident but fragile.
Pricing
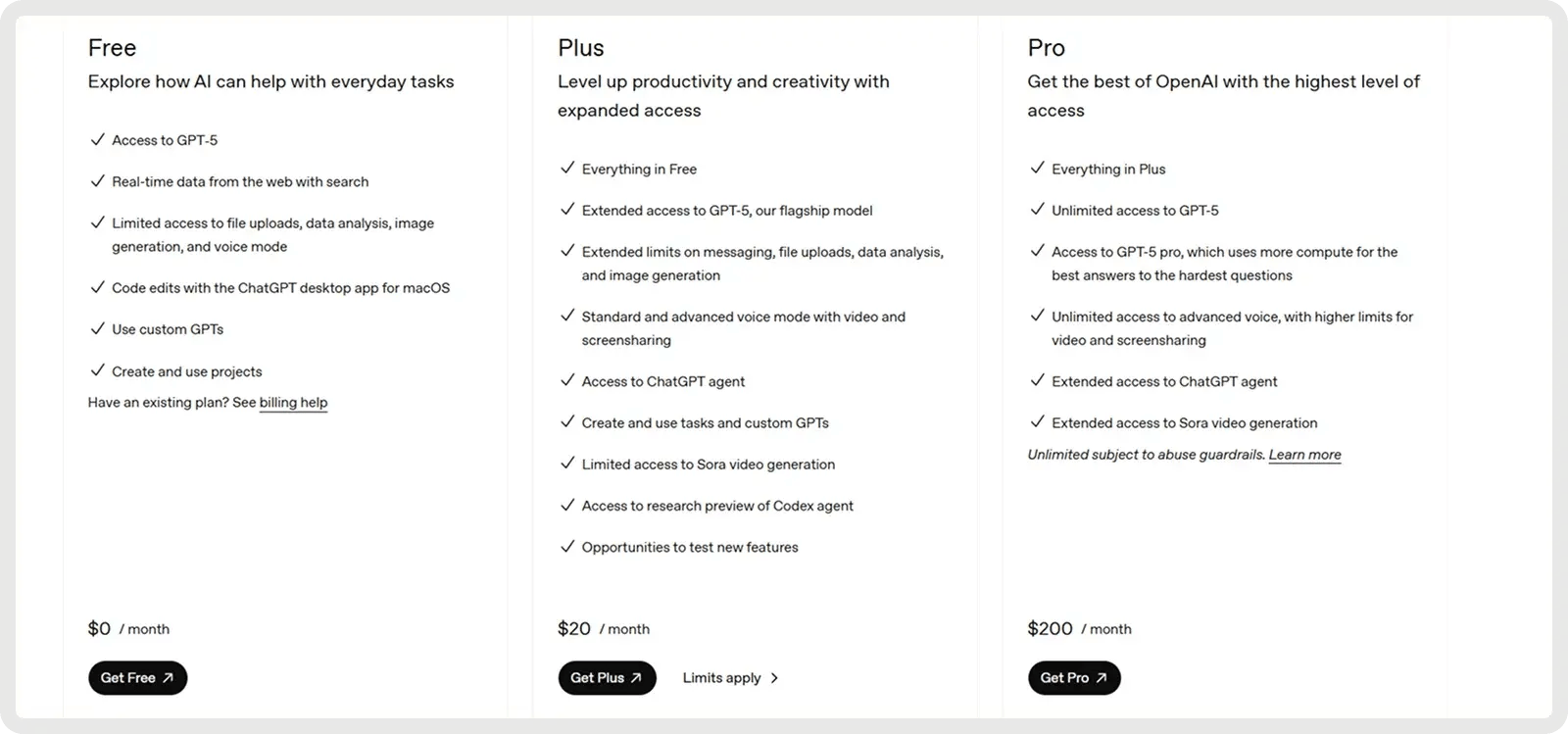
OpenAI’s GPT-5 offers a Free Plan and 2 Paid Plans starting at $20 per month.
2. Best for Complex Debugging: Anthropic Claude 4 (Sonnet 4)
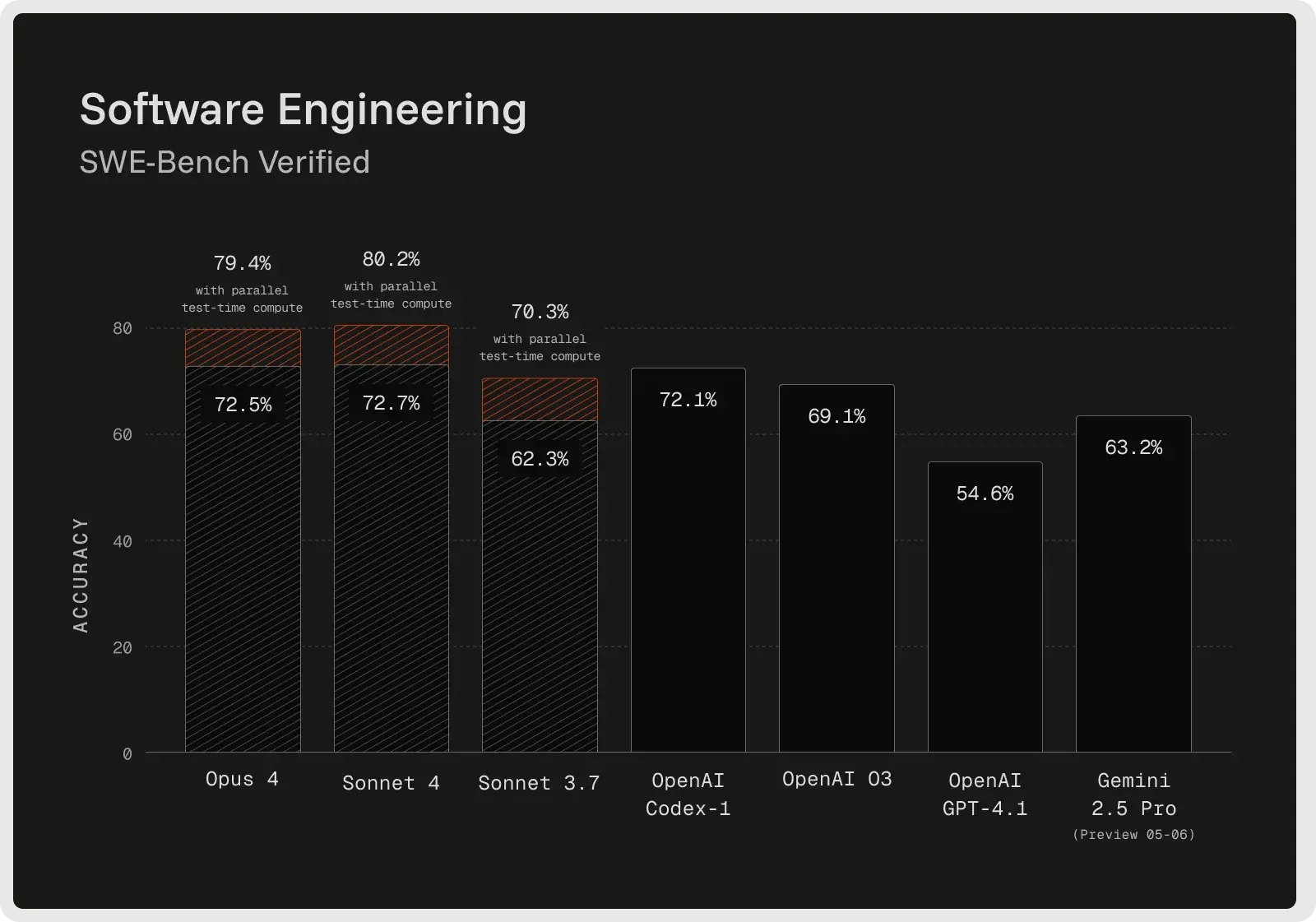
Claude Sonnet 4 is built for advanced reasoning and performs strongly in complex debugging and code review. The model often outlines a plan before making edits, which improves clarity and helps catch issues earlier in the process. On the SWE-Bench Verified benchmark, it achieved 72.7% accuracy on real-world bug fixes, setting a new record and outperforming most competitors. Its extended thinking mode allows for up to 128K tokens, enabling it to process large codebases and supporting documents while reducing hallucinations through clarifying questions. Developers report fewer errors, more reliable handling of ambiguous requests, and safer incremental fixes compared to one-shot approaches.
Key Capabilities:
- Full lifecycle development – Supports the entire process from planning and design to refactoring, debugging, and long-term maintenance.
- Instruction following & tool use – Selects and integrates external tools (e.g., file APIs, code execution) into workflows as needed.
- Error detection & debugging – Identifies, explains, and resolves bugs with clear reasoning for code edits.
- Refactoring & code transformation – Performs large-scale restructuring across files or entire codebases.
- Precision generation & planning – Produces clean, structured code aligned with design and project goals.
- Long-context reasoning – Maintains coherence across extended contexts for large codebases or lengthy documents.
- Reliable logic adherence – Avoids brittle shortcuts and follows intended logic with greater consistency.
Pros and Cons:
🟢 Pros:
- Strong at generating and completing larger coding tasks.
- Follows instructions more reliably than earlier versions.
- Balanced cost vs performance compared to Opus.
- Provides clear, well-structured code outputs.
🔴 Cons:
- Can misunderstand simple requests or over-explain.
- Weaker at OCR and document-heavy coding tasks.
- Struggles with very complex, multi-step problem solving.
- Output consistency can vary between coding domains.
Pricing
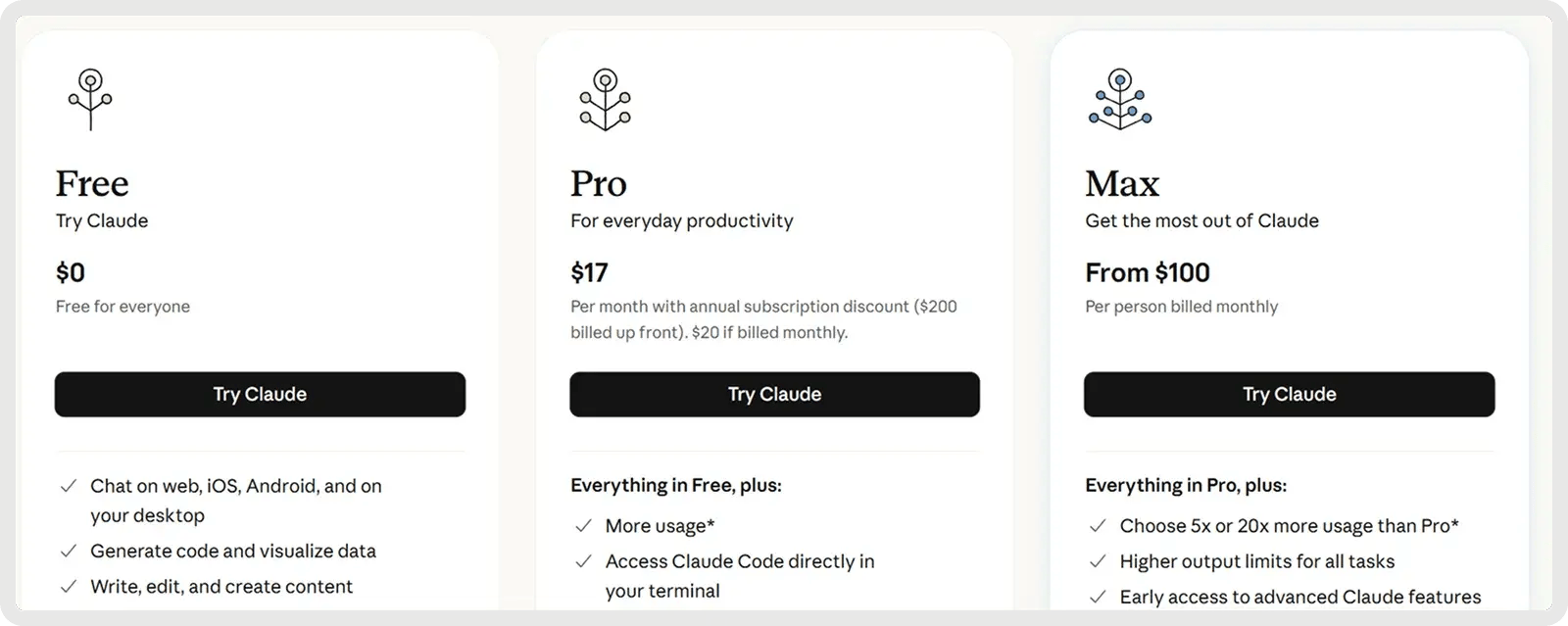
Claude offers a Free Plan and 2 Paid Plans starting at 17$ per month.
3. Best for Large Codebases & Full Stack: Google Gemini 2.5 Pro
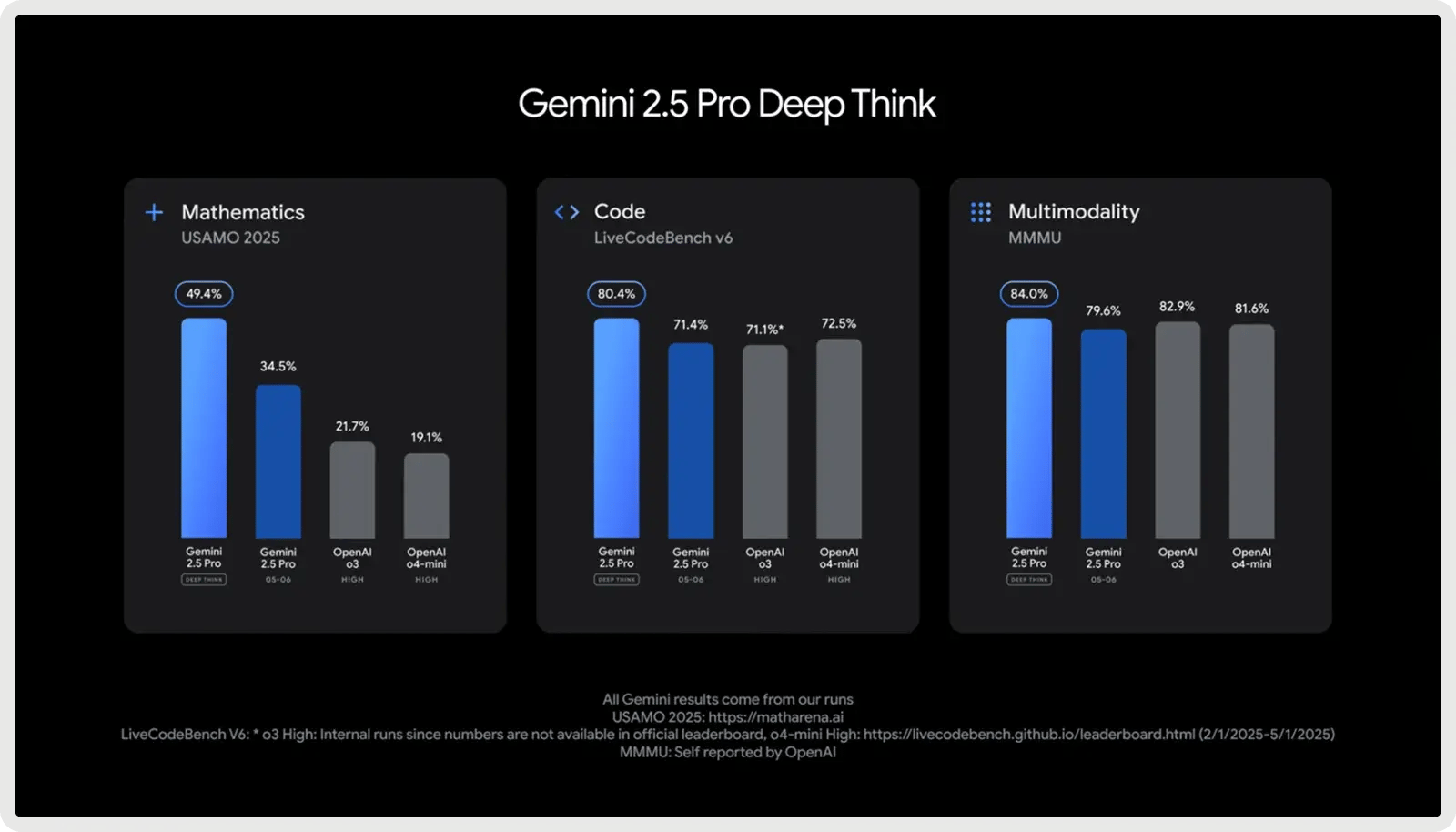
Google Gemini 2.5 Pro is designed for large-scale coding projects, featuring a 1,000,000-token context window that enables it to handle entire repositories, test suites, and migration scripts in a single pass. It’s optimized for software development, excelling at generating, debugging, and refactoring code across multiple files and frameworks. It supports complex coding workflows, from handling multi-file dependencies to reasoning about database queries and API integrations. With fast responses and full-stack awareness, it helps developers write, analyze, and integrate code across frontend, backend, and data layers seamlessly.
Key Capabilities:
- Code generation – Creates new functions, modules, or entire applications from prompts or specifications.
- Code editing – Applies targeted fixes, improvements, or refactoring directly within existing codebases.
- Multi-step reasoning – Breaks down complex programming tasks into logical steps and executes them reliably.
- Frontend/UI development – Builds interactive web components, layouts, and styles from natural language or designs.
- Large codebase handling – Understands and navigates entire repositories with multi-file dependencies.
- MCP integration – Supports Model Context Protocol for seamless use of open-source coding tools.
- Controllable reasoning – Adjusts its depth of problem solving (“thinking mode”) to balance accuracy, speed, and cost.
Pros and Cons:
🟢 Pros:
- Excels at generating full solutions from scratch.
- Handles large codebases with 1M-token context.
- Strong benchmark performance in coding tasks.
- Deep Think boosts reasoning for complex problems.
🔴 Cons:
- Weaker at debugging and code fixes.
- Sometimes hallucinates or changes code unasked.
- Verbose outputs and format inconsistencies.
- Mixed reliability compared to earlier versions.
Pricing
Google Gemini 2.5 Pro offers a Free Plan and Paid Plan starting at $1.25 per million input tokens and $10 per million output tokens. Additional rates apply for prompts exceeding 200k tokens, along with optional caching and grounding fees.
4. Best Value (Open-Source): DeepSeek V3.1/R1

DeepSeek’s V3.1 and R1 models offer strong value for developers seeking both affordability and open-source flexibility. These Mixture-of-Experts models, licensed under the MIT license, are specifically optimized for math and coding tasks. The R1 model is fine-tuned with reinforcement learning for advanced reasoning and logic, demonstrating performance that matches or exceeds that of older OpenAI models and approaches the Gemini 2.5 Pro on complex reasoning benchmarks.
Key Capabilities:
- Mixture-of-experts efficiency – Activates only a subset of experts per query, delivering high capacity while keeping inference costs lower than dense models.
- Reinforcement learning for reasoning (R1) – Fine-tuned with RL to improve chain-of-thought reasoning, logical inference, and step-by-step accuracy.
- Advanced math & logic performance – Strong results on benchmarks like MATH and AIME, making it especially good at symbolic reasoning and problem solving.
- Self-cerification & reflection – Generates internal reasoning chains and can self-check answers, improving reliability on complex, multi-step tasks.
- Open-source & MIT licensed – Fully permissive license enables inspection, modification, and unrestricted commercial use, unlike most proprietary LLMs.
- Scalability & deployment options – Supports quantization and distilled variants, allowing use on smaller hardware with minimal performance loss.
- Multilingual support – Trained on multiple languages (including English and Chinese), enabling broader applicability for global developers.
Pros and Cons:
🟢 Pros:
- Generates complete, functional solutions with high reliability.
- Supports large codebases with an extended 128k context.
- “Think” mode enhances reasoning for complex programming tasks.
- Open-weight model with lower operating costs.
🔴 Cons:
- Limited precision in following detailed coding instructions.
- Verbose outputs, particularly in reasoning mode.
- Trails leading models in code quality.
- Potential security and alignment risks in generated code.
Pricing
V3.1 is a cost-effective, general-purpose model, with input tokens priced at $0.07 per 1 million (cache hit) or $0.56 per 1 million (cache miss), and output tokens at $1.68 per 1 million. This makes it highly attractive for high-volume use cases, especially where caching is effective.
R1, positioned as a premium reasoning model, costs approximately $0.14 per million input tokens and about $2.19 per million output tokens.
5. Best Open-Source (Large Context): Meta Llama 4
Meta’s newest open models, Llama 4 Scout and Maverick (released in April 2025), dramatically expand context length, with Scout (17B parameters) supporting up to 10 million tokens and handling multimodal input. Scout demonstrates significant improvements in coding, achieving stronger accuracy on benchmarks such as MBPP and demonstrating better handling of long, multi-file programming tasks compared to Llama 3. Developers can use Scout to manage complex coding tasks such as multi-file refactors, dependency tracking, or end-to-end system analysis without the model “forgetting” earlier context. Because it’s open-source and commercially usable, teams can fine-tune it for their own workflows and run it securely on local hardware.
Key Capabilities:
- Code generation – Produces accurate, functional code across a wide range of programming tasks.
- Interactive coding – Supports real-time code completion, editing, and debugging assistance.
- Function calling – Generates structured outputs (e.g., JSON) to call APIs or integrate with external tools.
- Large-scale code handling – Manages entire repositories or multi-file projects without losing context, thanks to its 10M-token window.
- Instruction following – Adapts precisely to coding-specific prompts for tasks like bug fixes, refactoring, or algorithm design.
- Efficient deployment – Runs effectively on local hardware, making large-scale coding assistance more accessible.
- Code reasoning – Understands dependencies and semantics within codebases, supporting deeper analysis and system-level insights.
Pros and Cons:
🟢 Pros:
- Fast inference, practical for local coding use.
- Competitive coding scores among open models.
- Handles very long code/context windows.
- Open-weight and customizable for private use.
🔴 Cons:
- Trails top models (GPT-5, Claude) in coding accuracy.
- Inconsistent or buggy in edge-case coding tasks.
- Output style can feel dry or synthetic.
- Limited adoption feedback.
Pricing
Llama 4 pricing is currently around $0.15/M input and $0.50/M output tokens for Scout, and $0.22–0.27/M input and $0.85/M output tokens for Maverick, varying slightly by provider.
6. Best for Collaborative Debugging & Long-Context Tasks: Claude Sonnet 4.5
Claude Sonnet 4.5 is Anthropic’s latest and most capable hybrid reasoning model, expanding on Sonnet 4 with sharper intelligence, faster code generation, and improved agentic coordination. It features a 200K-token context window, stronger tool-use accuracy, and refined domain knowledge across coding, finance, and cybersecurity. Optimized for extended reasoning and large-scale collaboration, it excels at managing complex coding projects, autonomous agents, and long-form analytical tasks.
Key Capabilities:
- End-to-end code generation – Handles the entire software development lifecycle, from planning and implementation to debugging, refactoring, and maintenance.
- Advanced reasoning – Performs multi-step logical analysis and follows complex instructions to solve sophisticated programming challenges.
- Automated error correction – Detects, explains, and fixes code issues in real time to enhance reliability and reduce debugging effort.
- Extended context window – Supports up to 64K tokens for understanding large codebases, design documents, and project-wide dependencies without losing context.
- Autonomous tool integration – Selects and operates appropriate development tools such as compilers, interpreters, and version control systems for streamlined workflows.
- Proactive cybersecurity – Identifies, mitigates, and patches vulnerabilities autonomously to maintain secure and resilient codebases.
- Persistent agent operation – Executes long-running coding tasks and manages multi-stage workflows continuously across sessions.
Pros and Cons:
🟢 Pros:
- Strong reasoning and coding accuracy across tasks.
- Excellent context retention and multi-file awareness.
- Efficient tool use and structured problem-solving.
- Capable of longer, more autonomous coding sessions.
🔴 Cons:
- Slower responses during deep reasoning or planning.
- Occasional instruction drift and factual mistakes.
- Still limited context window for very large projects.
- Struggles with interactive environments
Pricing
Pricing for Sonnet 4.5 starts at $3 per million input tokens and $15 per million output tokens.

From Models to Workflows: Making LLMs Practical with Zencoder
Now that you know the 6 best LLMs for coding, the next question is how to actually put them to work in your day-to-day development. Even the most advanced models still require a suitable system to integrate with your tools, automate workflows, and deliver consistent results across large projects.
That’s where Zencoder comes! It lets you plug your favorite model (or models) into a production-grade coding agent that streamlines workflows, handles integration, and ensures reliability at scale.
What is Zencoder

Zencoder is an AI-powered coding agent that enhances the software development lifecycle (SDLC) by improving productivity, accuracy, and creativity through advanced artificial intelligence solutions. With its Repo Grokking™ technology, Zencoder thoroughly analyzes your entire codebase, uncovering structural patterns, architectural logic, and custom implementations.
Additionally, with universal tool compatibility, you can bring your own CLI, including Claude Code, OpenAI Codex, or Google Gemini, directly into your IDE with full context. It also delivers multi-repo intelligence, enabling Zencoder to understand enterprise-scale codebases, service connections, and dependency propagation.
Here are some of Zencoder's key features:
1️⃣ Integrations – Seamlessly integrates with over 20 developer environments, simplifying your entire development lifecycle. This makes Zencoder the only AI coding agent offering this extensive level of integration.
4️⃣ All-in-One AI Coding Assistant – Speed up your development workflow with an integrated AI solution that provides intelligent code completion, automatic code generation, and real-time code reviews.
- Code Completion – Smart code suggestions keep your momentum going with context-aware, accurate completions that reduce errors and enhance productivity.
- Code Generation – Produces clean, consistent, and production-ready code tailored to your project’s needs, perfectly aligned with your coding standards.
- Code Review Agent – Continuous code review ensures every line meets best practices, catches potential bugs, and improves security through precise, actionable feedback.
- Chat Assistant – Receive instant, reliable answers and personalized coding support. Stay productive with intelligent recommendations that keep your workflow smooth and efficient.
3️⃣ Security treble – Zencoder is the only AI coding agent with SOC 2 Type II, ISO 27001 & ISO 42001 certification.
5️⃣ Zentester – Zentester uses AI to automate testing at every level, so your team can catch bugs early and ship high-quality code faster. Just describe what you want to test in plain English, and Zentester takes care of the rest, adapting as your code evolves.
Watch Zentester in action:
Here is what it does:
- Our intelligent agents understand your app and interact naturally across UI, API, and database layers.
- As your code changes, Zentester automatically adapts your tests, eliminating the need for constant rewriting.
- From unit functions to end-to-end user flows, every layer of your app is thoroughly tested at scale.
- Zentester’s AI identifies risky code paths, uncovers hidden edge cases, and creates tests based on how real users interact with your app.
6️⃣ Zen Agents – Zen Agents are fully customizable AI teammates that understand your code, integrate seamlessly with your existing tools, and can be deployed in seconds.

With Zen Agents, you can:
- Build smarter – Create specialized agents for tasks like pull request reviews, testing, or refactoring, tailored to your architecture and frameworks.
- Integrate fast – Connect to tools like Jira, GitHub, and Stripe in minutes using our no-code MCP interface, so your agents run right inside your existing workflows.
- Deploy instantly – Deploy agents across your organization with one click, with auto-updates and shared access to keep teams aligned and expertise scalable.
- Explore marketplace – Browse a growing library of open-source, pre-built agents ready to drop into your workflow, or contribute your own to help the community move faster.
Get started with Zencoder for free and turn any LLM into a production-ready coding agent!



