
Los grandes modelos de lenguaje (LLM ) se están convirtiendo rápidamente en una parte esencial del desarrollo de software moderno. Una investigación reciente indica que más de la mitad de los desarrolladores senior (53%) creen que estas herramientas ya pueden codificar con más eficacia que la mayoría de los humanos. Estos modelos se utilizan a diario para depurar errores complicados, generar funciones más limpias y revisar el código, ahorrando horas de trabajo a los desarrolladores. Pero con la rápida aparición de nuevos LLM, no siempre es fácil saber cuáles merece la pena adoptar. Por eso hemos creado una lista de los 6 mejores LLM para codificación que pueden ayudarte a codificar de forma más inteligente, ahorrar tiempo y aumentar tu productividad.

Los 6 mejores LLM en codificación a tener en cuenta en 2026
Antes de profundizar en nuestras mejores selecciones, esto es lo que te espera:
|
Modelo |
Mejor para |
Precisión |
Razonamiento |
Ventana de contexto |
Coste |
Soporte del ecosistema |
Disponibilidad de código abierto |
|
GPT-5 (OpenAI) |
Mejor en general |
74,9% (SWE-bench) / 88% (Aider Polyglot) |
Razonamiento en varios pasos, flujos de trabajo colaborativos |
400K tokens (272K de entrada + 128K de salida) |
Gratuito + planes de pago a partir de 20 $/mes |
Muy potente (plugins, herramientas, integración con desarrolladores) |
Cerrado |
|
Claude 4 Sonnet (Antrópico) |
Depuración compleja |
72,7% (verificado por SWE-bench) |
Depuración avanzada, planificación, seguimiento de instrucciones |
128K tokens |
Planes gratuitos + de pago a partir de 17 $/mes |
Ecosistema en crecimiento con integraciones de herramientas |
Cerrado |
|
Gemini 2.5 Pro (Google) |
Grandes bases de código y pila completa |
Verificado por SWE-bench: ~63,8% (codificación ágil); LiveCodeBench: ~70,4%; Aider Polyglot: ~74,0%. |
Razonamiento controlado ("Deep Think"), flujos de trabajo en varios pasos |
1.000.000 de tokens |
1,25 $ por millón de entrada + 10 $ por millón de salida |
Fuerte (herramienta Google e integración API) |
Cerrado |
|
DeepSeek V3.1 / R1 |
Mejor valor (código abierto) |
Iguala los modelos OpenAI más antiguos, se acerca a Gemini en razonamiento |
Lógica ajustada a RL y autorreflexión |
128K tokens |
Entrada: 0,07-0,56 $/M, Salida: $1.68-2.19/M |
Media (adopción de código abierto, flexibilidad para desarrolladores) |
Abierto (licencia MIT) |
|
Llama 4 (Meta: Scout / Maverick) |
Código abierto (contexto amplio) |
Buen rendimiento de codificación y razonamiento en pruebas comparativas de modelos abiertos |
Buen razonamiento paso a paso (menos avanzado que GPT-5/Claude) |
Hasta 10 millones de fichas (Scout) |
0,15-0,50 $/M de entrada, 0,50-0,85 $/M de salida |
Creciente ecosistema de código abierto, herramientas para desarrolladores |
Pesos abiertos |
|
Claude Sonnet 4.5 (Antrópico) |
Depuración colaborativa y tareas de contexto largo |
Estimación ~75-77% (clase SWE-bench) |
Razonamiento agéntico híbrido, uso autónomo de herramientas y planificación |
200.000 fichas |
3 $/M de entrada + 15 $/M de salida |
Ampliación del ecosistema antrópico con cadenas de herramientas agénticas |
Cerrado |
1. Mejor en general: GPT-5 de OpenAI
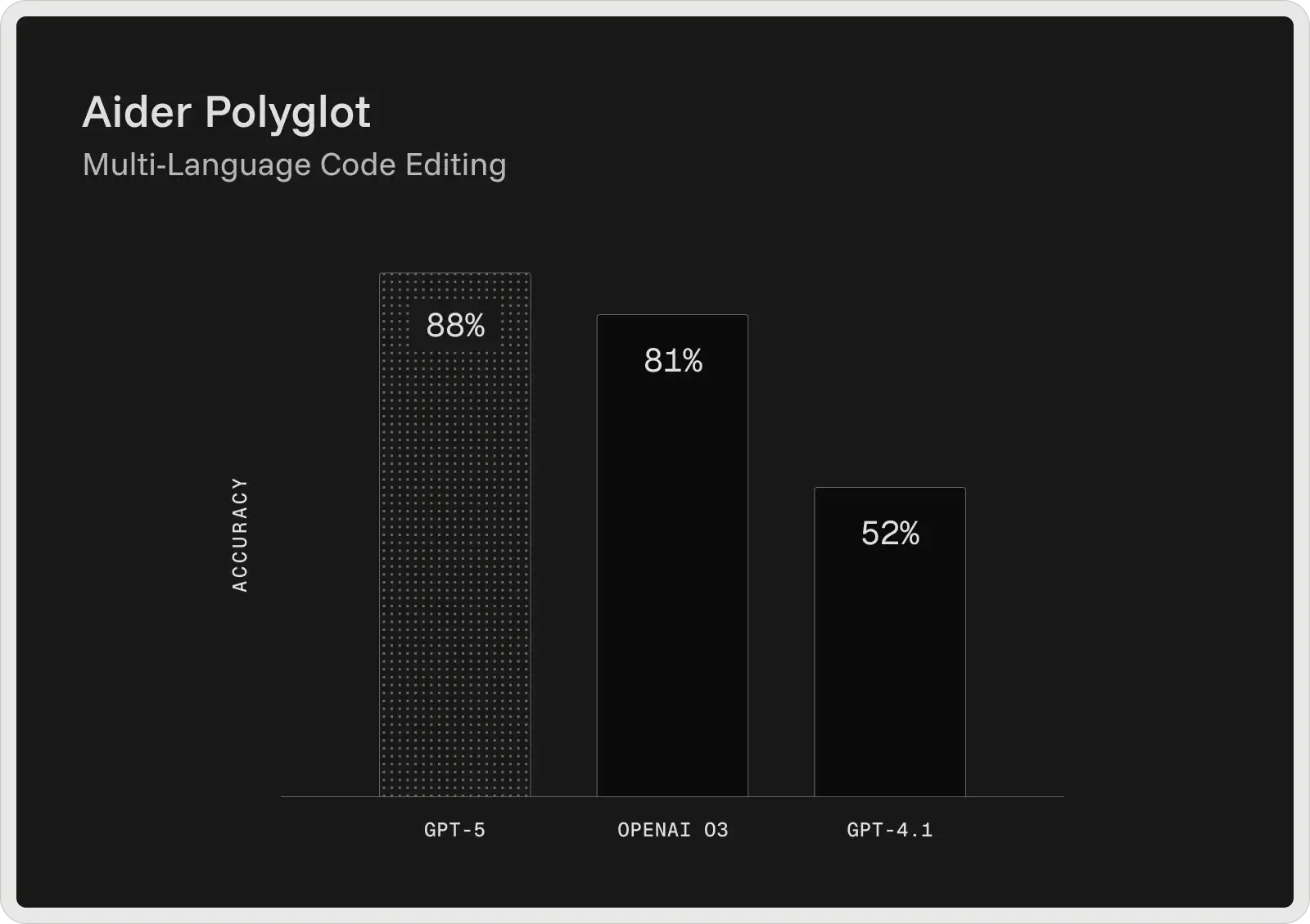
El GPT-5 de OpenAI es actualmente el modelo de codificación más potente de su gama y ofrece los mejores resultados en las pruebas de referencia más utilizadas por los desarrolladores. En el SWE-bench Verified, alcanza una precisión del 74,9%, y en Aider Polyglot, del 88%, reduciendo las tasas de error en comparación con modelos anteriores, como GPT-4.1 y o3. Diseñado como asistente de codificación colaborativa, GPT-5 puede generar y editar código, corregir errores y responder con coherencia a preguntas complejas sobre grandes bases de código.
Proporciona explicaciones antes y entre los pasos, sigue instrucciones detalladas de forma fiable y puede ejecutar tareas de codificación en varias fases sin perder de vista el contexto. En las pruebas internas, también fue el preferido para el desarrollo de front-end, donde los desarrolladores prefirieron sus resultados a los de o3 alrededor del 70% de las veces.
Funciones clave:
- Ventana de contexto de 400.000 tokens: gestiona 272.000 tokens de entrada y 128.000 de salida, lo que permite el análisis a escala de repositorio, la ingestión de documentación y el razonamiento multiarchivo.
- Detección y depuración avanzada de errores : identifica problemas ocultos en grandes bases de código y proporciona correcciones validadas con un razonamiento claro.
- Integración y encadenamiento de herramientas : llama a herramientas externas de forma fiable y admite flujos de trabajo secuenciales y paralelos con menos fallos.
- Fidelidad a las instrucciones: sigue al pie de la letra las instrucciones detalladas de los desarrolladores, incluso en tareas de varios pasos o muy limitadas.
- Flujos de trabajo colaborativos : comparte planes, pasos intermedios y actualizaciones de progreso durante sesiones de codificación de larga duración.
- Razonamiento en contextos amplios: mantiene la coherencia en proyectos de gran envergadura, conservando las dependencias y la lógica en cientos de miles de tokens.
- Recuperación fiable de contenidos: alto rendimiento en pruebas de recuperación de contexto largo (por ejemplo, OpenAI-MRCR, BrowseComp), lo que le permite localizar y utilizar información oculta en entradas muy grandes.
Pros y contras:
Pros:
- Maneja tareas de codificación más largas y grandes bases de código con mayor eficacia.
- Sigue instrucciones detalladas con mayor precisión.
- Capta errores sutiles que otros modelos suelen pasar por alto.
- Produce respuestas más limpias y menos "alucinadas" en algunos casos.
- Lucha por implementar completamente planes complejos de varios pasos.
- A veces alucina o deja el código incompleto.
- Velocidad de respuesta más lenta y calidad de salida inconsistente.
- El código generado puede ser demasiado confiado pero frágil.
Precios
GPT-5 de OpenAI ofrece un plan gratuito y 2 planes de pago a partir de 20 dólares al mes.
2. Lo mejor para depuración compleja: Antropic Claude 4 (Soneto 4)
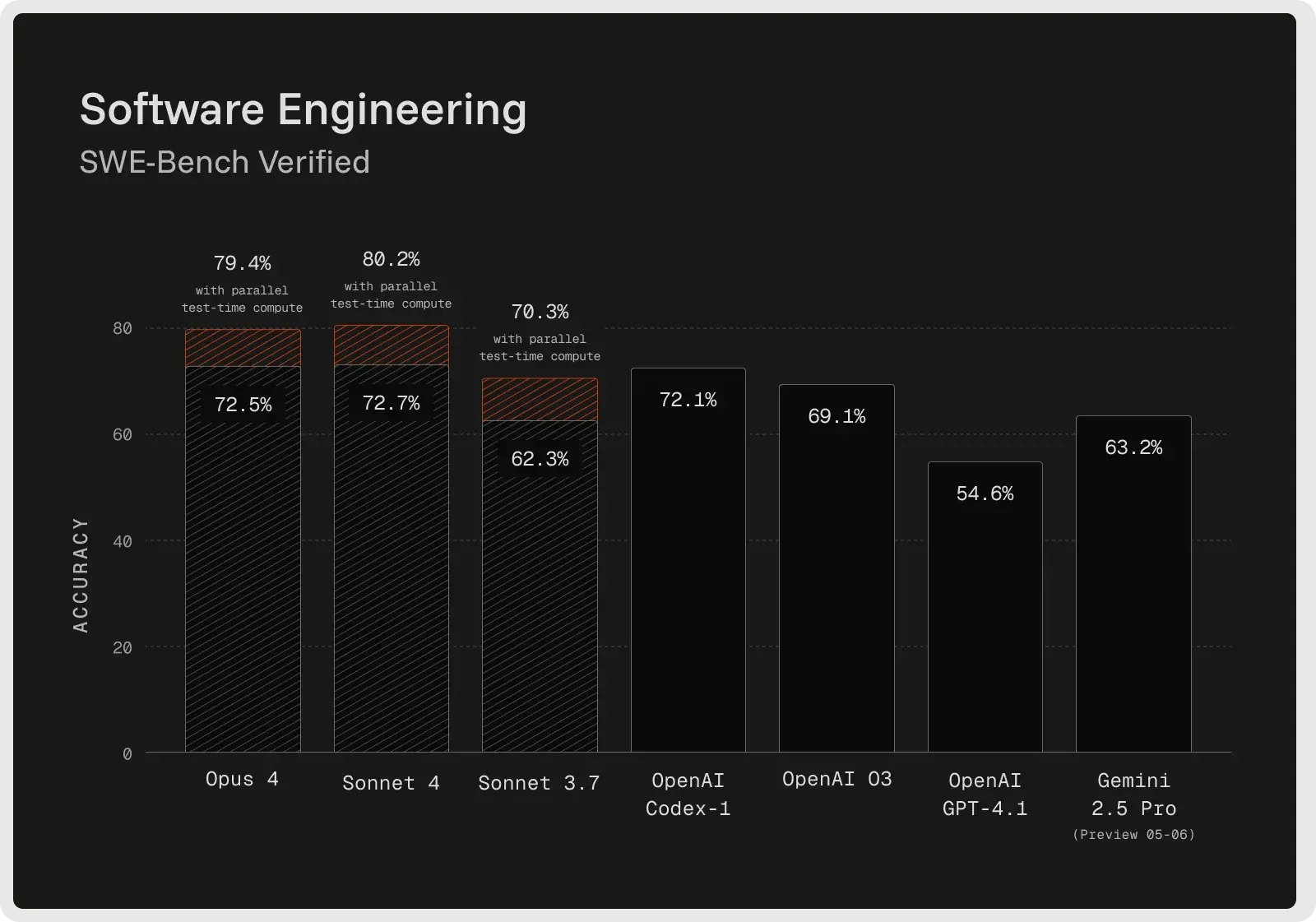
Claude Sonnet 4 está construido para el razonamiento avanzado y tiene un gran rendimiento en depuración compleja y revisión de código. El modelo suele esbozar un plan antes de realizar modificaciones, lo que mejora la claridad y ayuda a detectar problemas en una fase más temprana del proceso. En la prueba de referencia SWE-Bench Verified, alcanzó una precisión del 72,7% en la corrección de errores del mundo real, estableciendo un nuevo récord y superando a la mayoría de los competidores. Su modo de pensamiento ampliado admite hasta 128.000 tokens, lo que le permite procesar grandes bases de código y documentos de apoyo al tiempo que reduce las alucinaciones mediante preguntas aclaratorias. Los desarrolladores informan de menos errores, un manejo más fiable de las peticiones ambiguas y correcciones incrementales más seguras en comparación con los enfoques únicos.
Funciones clave:
- Desarrollo del ciclo de vida completo - Da soporte a todo el proceso, desde la planificación y el diseño hasta la refactorización, la depuración y el mantenimiento a largo plazo.
- Seguimiento de instrucciones y uso de herramientas: selecciona e integra herramientas externas (por ejemplo, API de archivos, ejecución de código) en los flujos de trabajo según sea necesario.
- Detección y depuración de errores - Identifica, explica y resuelve errores con un razonamiento claro para las ediciones de código.
- Refactorización y transformación de código : realiza reestructuraciones a gran escala en archivos o bases de código completas.
- Generación y planificación precisas : genera código limpio y estructurado en consonancia con el diseño y los objetivos del proyecto.
- Razonamiento en contextos amplios: mantiene la coherencia en contextos amplios para bases de código de gran tamaño o documentos extensos.
- Adhesión lógica fiable: evita los atajos frágiles y sigue la lógica prevista con mayor coherencia.
Ventajas e inconvenientes:
🟢 Pros:
- Fuerte a la hora de generar y completar tareas de codificación más grandes.
- Sigue las instrucciones de forma más fiable que las versiones anteriores.
- Coste y rendimiento equilibrados en comparación con Opus.
- Proporciona salidas de código claras y bien estructuradas.
- Puede malinterpretar peticiones sencillas o dar demasiadas explicaciones.
- Más débil en OCR y tareas de codificación de documentos pesados.
- Le cuesta resolver problemas complejos de varios pasos.
- La coherencia de los resultados puede variar según el ámbito de codificación.
Precios
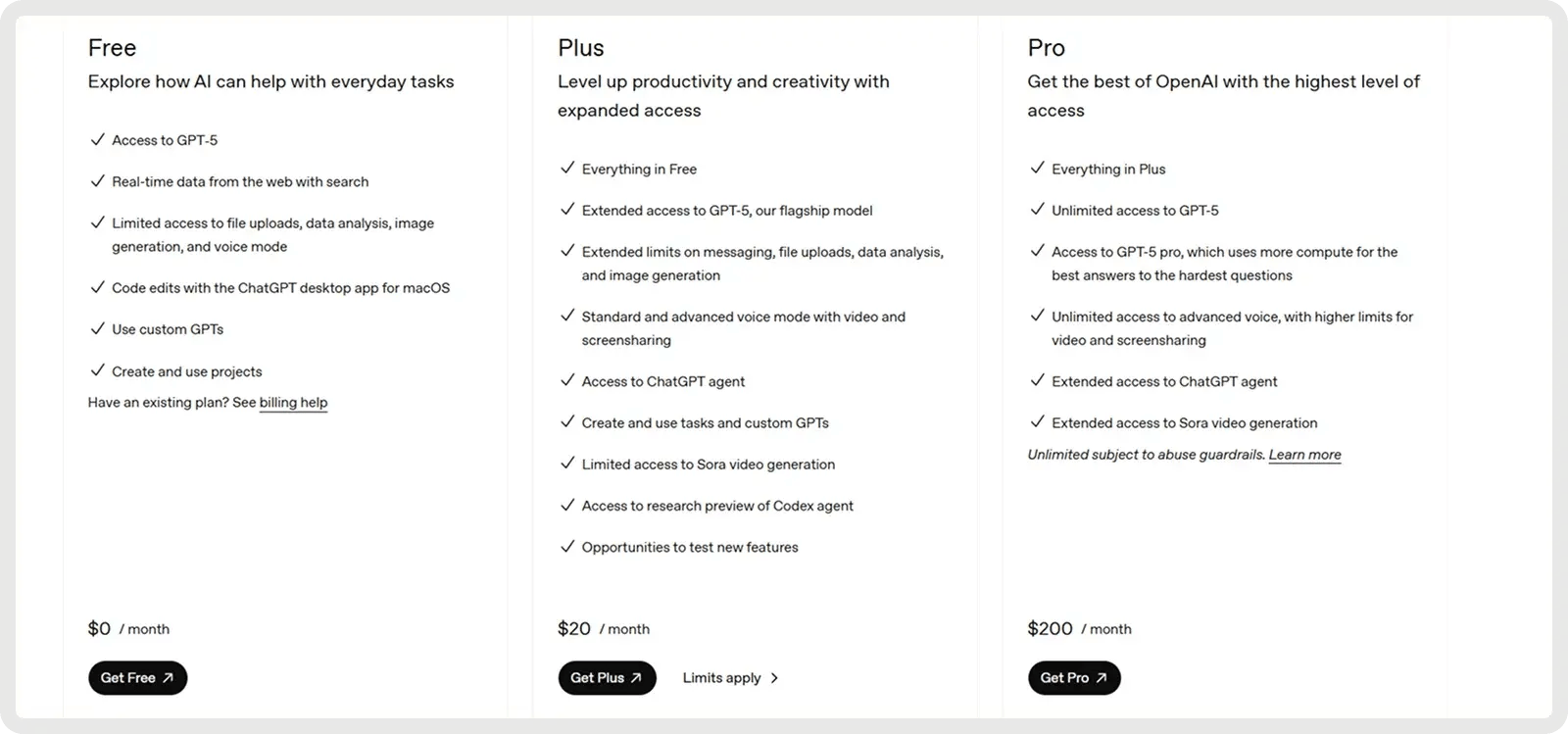
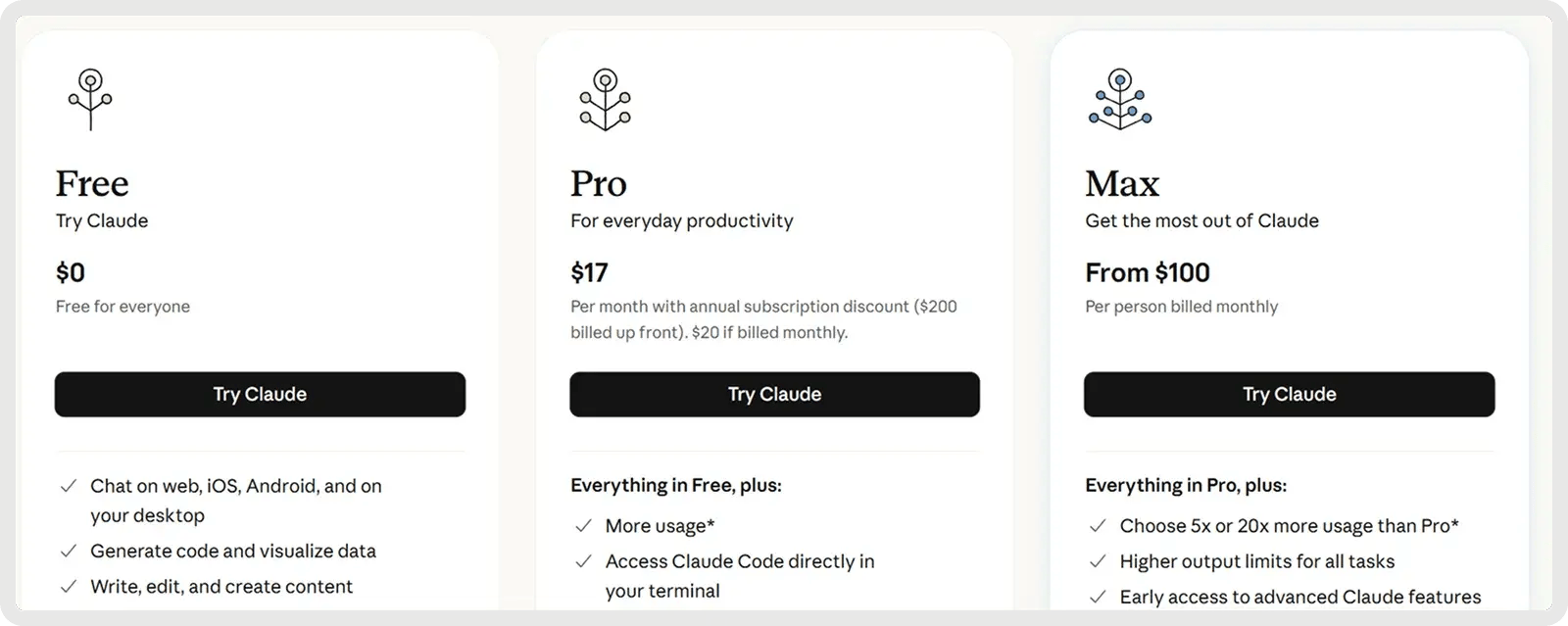
Claude ofrece un plan gratuito y 2 planes de pago a partir de 17 $ al mes.
3. Lo mejor para grandes bases de código y Full Stack: Google Gemini 2.5 Pro
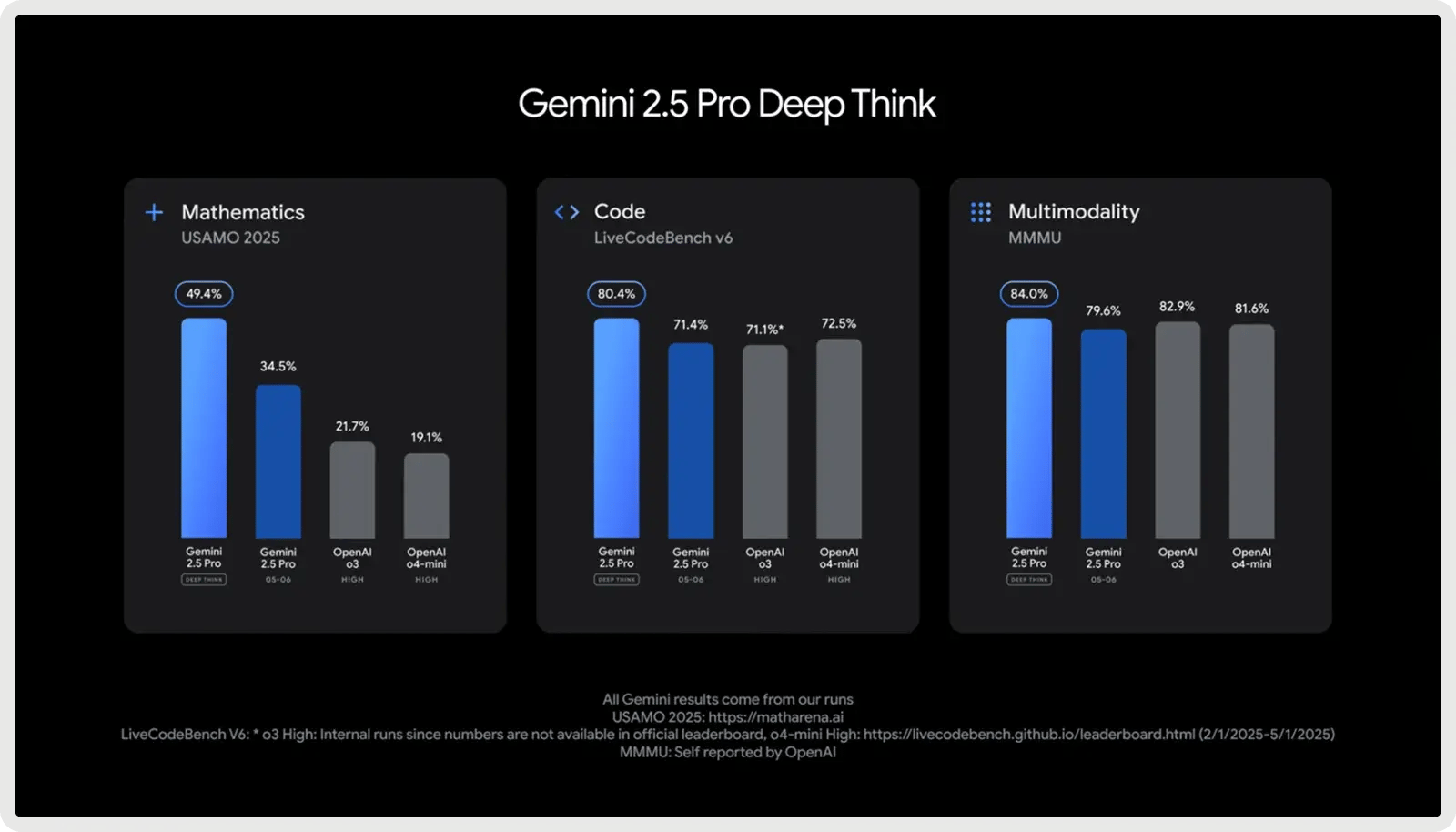
Google Gemini 2.5 Pro está diseñado para proyectos de codificación a gran escala, con una ventana contextual de 1.000.000 de tokens que le permite gestionar repositorios enteros, conjuntos de pruebas y scripts de migración en una sola pasada. Está optimizado para el desarrollo de software, destacando en la generación, depuración y refactorización de código a través de múltiples archivos y marcos de trabajo. Admite flujos de trabajo de codificación complejos, desde la gestión de dependencias de varios archivos hasta el razonamiento sobre consultas de bases de datos e integraciones de API. Con respuestas rápidas y un conocimiento completo de la pila, ayuda a los desarrolladores a escribir, analizar e integrar código en frontend, backend y capas de datos sin problemas.
Funciones clave:
- Generación de código : crea nuevas funciones, módulos o aplicaciones completas a partir de instrucciones o especificaciones.
- Edición de código: aplica correcciones, mejoras o refactorizaciones específicas directamente en las bases de código existentes.
- Razonamiento en varios pasos: descompone tareas de programación complejas en pasos lógicos y los ejecuta de forma fiable.
- Desarrollo Frontend/UI : crea componentes web interactivos, diseños y estilos a partir de lenguaje natural o diseños.
- Gestión de grandes bases de código: comprende y navega por repositorios enteros con dependencias de varios archivos.
- Integración MCP - Admite el protocolo de contexto de modelo para el uso sin problemas de herramientas de codificación de código abierto.
- Razonamiento controlable : ajusta la profundidad de la resolución de problemas ("modo de pensamiento") para equilibrar precisión, velocidad y coste.
Pros y contras:
🟢 Pros:
- Sobresale en la generación de soluciones completas desde cero.
- Maneja grandes bases de código con un contexto de 1M de tokens.
- Gran rendimiento en tareas de codificación.
- Deep Think potencia el razonamiento en problemas complejos.
- Más débil en depuración y corrección de código.
- A veces alucina o cambia código sin preguntar.
- Salidas verborreicas e inconsistencias de formato.
- Fiabilidad dispar en comparación con versiones anteriores.
Precios
Google Gemini 2.5 Pro ofrece un plan gratuito y un plan de pago a partir de 1,25 dólares por millón de tokens de entrada y 10 dólares por millón de tokens de salida. Se aplican tarifas adicionales para solicitudes que superen los 200.000 tokens, junto con tarifas opcionales de almacenamiento en caché y conexión a tierra.
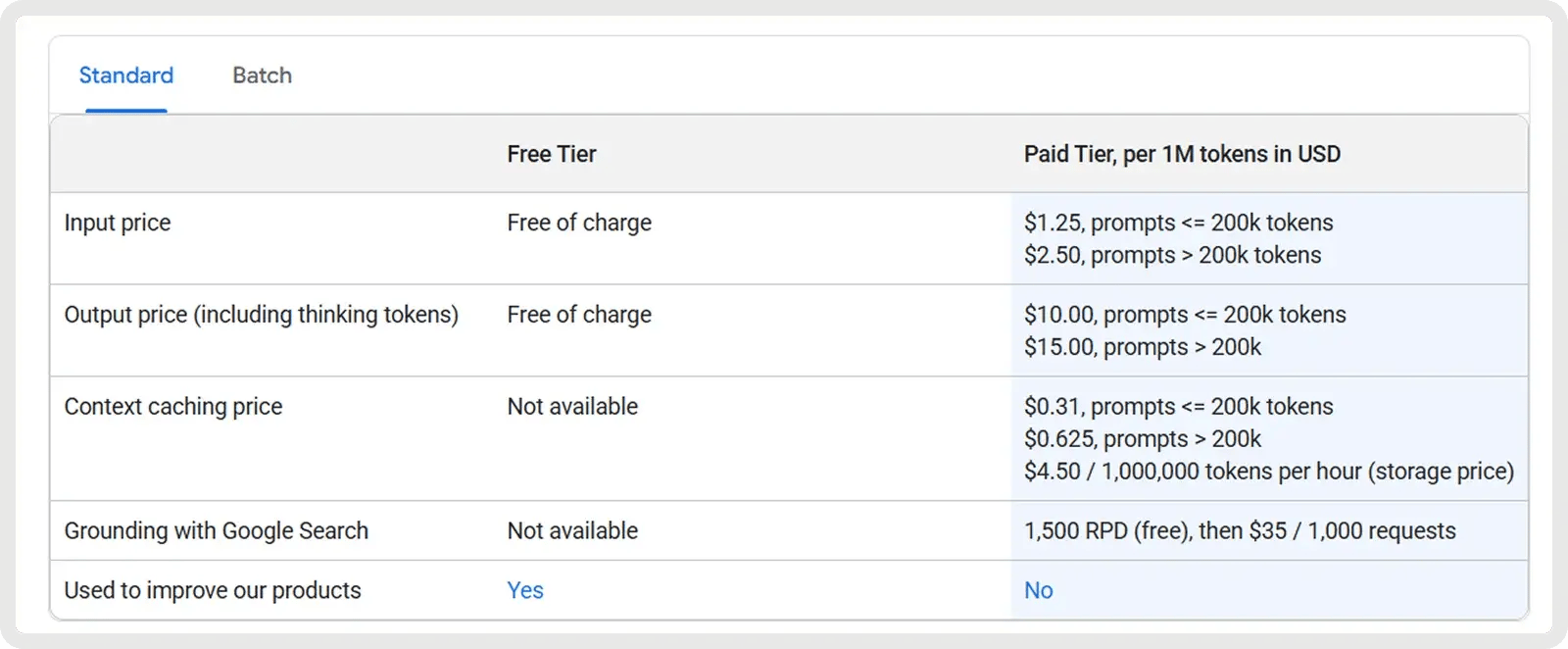
4. Mejor valor (código abierto): DeepSeek V3.1/R1

Los modelos V3.1 y R1 de DeepSeek ofrecen un gran valor a los desarrolladores que buscan tanto asequibilidad como flexibilidad de código abierto. Estos modelos de mezcla de expertos, con licencia MIT, están optimizados específicamente para tareas matemáticas y de codificación. El modelo R1 se ha perfeccionado con el aprendizaje por refuerzo para el razonamiento y la lógica avanzados, demostrando un rendimiento que iguala o supera el de los modelos OpenAI más antiguos y se acerca al Gemini 2.5 Pro en pruebas de razonamiento complejas.
Funciones clave:
- Eficacia de la mezcla de expertos: activa sólo un subconjunto de expertos por consulta, lo que proporciona una gran capacidad y mantiene los costes de inferencia más bajos que los modelos densos.
- Aprendizaje por refuerzo para el razonamiento (R1) - Perfeccionado con RL para mejorar el razonamiento por cadena de pensamiento, la inferencia lógica y la precisión paso a paso.
- Rendimiento avanzado en matemáticas y lógica: buenos resultados en pruebas como MATH y AIME, lo que lo hace especialmente bueno en razonamiento simbólico y resolución de problemas.
- Autocertificación y reflexión : genera cadenas de razonamiento internas y puede autocomprobar las respuestas, lo que mejora la fiabilidad en tareas complejas de varios pasos.
- Código abierto y licencia MIT - La licencia totalmente permisiva permite la inspección, la modificación y el uso comercial sin restricciones, a diferencia de la mayoría de los LLM propietarios.
- Escalabilidad y opciones de despliegue: admite cuantificación y variantes destiladas, lo que permite su uso en hardware más pequeño con una pérdida de rendimiento mínima.
- Soporte multilingüe - Capacitado en múltiples idiomas (incluyendo inglés y chino), lo que permite una mayor aplicabilidad para desarrolladores globales.
Pros y contras:
🟢 Pros:
- Genera soluciones completas y funcionales con alta fiabilidad.
- Soporta grandes bases de código con un contexto extendido de 128k.
- El modo "Think" mejora el razonamiento para tareas de programación complejas.
- Modelo de peso abierto con menores costes operativos.
🔴 Contras:
- Precisión limitada a la hora de seguir instrucciones de codificación detalladas.
- Salidas verborreicas, sobre todo en el modo de razonamiento.
- Sigue a los modelos líderes en calidad de código.
- Posibles riesgos de seguridad y alineación en el código generado.
Precios
V3.1 es un modelo rentable de uso general, con tokens de entrada a 0,07 dólares por millón (cache hit) o 0,56 dólares por millón (cache miss), y tokens de salida a1,68 dólares por millón. Esto lo hace muy atractivo para casos de uso de gran volumen, especialmente cuando el almacenamiento en caché es eficaz.
R1, posicionado como modelo de razonamiento premium, cuesta aproximadamente 0,14 dólares por millón de tokens de entrada y unos 2,19 dólares por millón de tokens de salida.
5. Mejor código abierto (contexto amplio): Meta Llama 4
Los modelos abiertos más recientes de Meta, Llama 4 Scout y Maverick (lanzados en abril de 2025), amplían drásticamente la longitud del contexto, con Scout (17B parámetros) soportando hasta 10 millones de tokens y manejando entrada multimodal. Scout demuestra mejoras significativas en la codificación, logrando una mayor precisión en pruebas de referencia como MBPP y demostrando un mejor manejo de tareas de programación largas y con varios archivos en comparación con Llama 3. Los desarrolladores pueden utilizar Scout para gestionar tareas de codificación complejas, como refactorizaciones de varios archivos, seguimiento de dependencias o análisis de sistemas de extremo a extremo sin que el modelo "olvide" el contexto anterior. Como es de código abierto y puede utilizarse comercialmente, los equipos pueden ajustarlo a sus propios flujos de trabajo y ejecutarlo de forma segura en hardware local.
Funciones clave:
- Generación de código: genera código preciso y funcional para una amplia gama de tareas de programación.
- Codificación interactiva: permite completar, editar y depurar código en tiempo real.
- Llamada a funciones - Genera salidas estructuradas (por ejemplo, JSON) para llamar a APIs o integrarse con herramientas externas.
- Gestión de código a gran escala: gestiona repositorios enteros o proyectos con varios archivos sin perder el contexto, gracias a su ventana de 10 millones de tokens.
- Seguimiento de instrucciones: se adapta con precisión a las instrucciones específicas de codificación para tareas como la corrección de errores, la refactorización o el diseño de algoritmos.
- Despliegue eficiente: se ejecuta eficazmente en hardware local, lo que hace más accesible la asistencia a la codificación a gran escala.
- Razonamiento del código: comprende las dependencias y la semántica de las bases de código, lo que permite un análisis más profundo y una mejor comprensión del sistema.
Pros y contras:
Pros:
- Inferencia rápida, práctico para el uso de codificación local.
- Puntajes de codificación competitivos entre los modelos abiertos.
- Maneja ventanas de código/contexto muy largas.
- Peso abierto y personalizable para uso privado.
- Por detrás de los mejores modelos (GPT-5, Claude) en precisión de codificación.
- Inconsistente o con errores en tareas de codificación de casos extremos.
- El estilo de salida puede parecer seco o sintético.
- Adopción limitada.
Precios
El precio de Llama 4 es actualmente de unos 0,15 $/M de entrada y 0,50 $/M de salida para Scout, y de 0,22-0,27 $/M de entrada y 0,85 $/M de salida para Maverick, variando ligeramente según el proveedor.
6. Mejor para depuración colaborativa y tareas de contexto largo: Claude Sonnet 4.5
Claude Sonnet 4.5 es el último y más capaz modelo de razonamiento híbrido de Anthropic, que amplía Sonnet 4 con una inteligencia más aguda, una generación de código más rápida y una mejor coordinación de los agentes. Cuenta con una ventana de contexto de 200.000 tokens, una mayor precisión en el uso de herramientas y un conocimiento refinado de los dominios de la codificación, las finanzas y la ciberseguridad. Optimizado para el razonamiento extendido y la colaboración a gran escala, destaca en la gestión de proyectos de codificación complejos, agentes autónomos y tareas analíticas de larga duración.
Funciones clave:
- Generación de código de extremo a extremo : gestiona todo el ciclo de vida del desarrollo de software, desde la planificación y la implementación hasta la depuración, la refactorización y el mantenimiento.
- Razonamiento avanzado: realiza análisis lógicos de varios pasos y sigue instrucciones complejas para resolver retos de programación sofisticados.
- Corrección automática de errores : detecta, explica y corrige problemas de código en tiempo real para mejorar la fiabilidad y reducir el esfuerzo de depuración.
- Ventana de contexto ampliada: admite hasta 64.000 tokens para comprender grandes bases de código, documentos de diseño y dependencias de todo el proyecto sin perder el contexto.
- Integración autónoma de herramientas : selecciona y utiliza las herramientas de desarrollo adecuadas, como compiladores, intérpretes y sistemas de control de versiones, para agilizar los flujos de trabajo.
- Ciberseguridad proactiva: identifica, mitiga y parchea vulnerabilidades de forma autónoma para mantener bases de código seguras y resistentes.
- Funcionamiento persistente del agente: ejecuta tareas de codificación de larga duración y gestiona flujos de trabajo multietapa de forma continua entre sesiones.
Pros y contras:
Pros:
- Fuerte razonamiento y precisión de codificación a través de tareas.
- Excelente retención de contexto y conciencia de archivos múltiples.
- Uso eficiente de herramientas y resolución estructurada de problemas.
- Capaz de sesiones de codificación más largas y autónomas.
- Respuestas más lentas durante el razonamiento profundo o la planificación.
- Desviación ocasional de las instrucciones y errores factuales.
- Ventana de contexto aún limitada para proyectos muy grandes.
- Problemas con los entornos interactivos.
Precios
El precio de Sonnet 4.5 comienza en 3 dólares por millón de tokens de entrada y 15 dólares por millón de tokens de salida.

De los modelos a los flujos de trabajo: Hacer que los LLM sean prácticos con Zencoder
Ahora que conoce los 6 mejores LLM para codificación, la siguiente cuestión es cómo ponerlos realmente en práctica en su desarrollo diario. Incluso los modelos más avanzados requieren un sistema adecuado para integrarse con sus herramientas, automatizar los flujos de trabajo y ofrecer resultados coherentes en proyectos de gran envergadura.
Ahí es donde entra Zencoder. Le permite conectar su modelo favorito (o modelos) a un agente de codificación de nivel de producción que agiliza los flujos de trabajo, gestiona la integración y garantiza la fiabilidad a escala.
Qué es Zencoder

Zencoder es un agente de codificación impulsado por IA que mejora el ciclo de vida de desarrollo de software (SDLC) al mejorar la productividad, la precisión y la creatividad a través de soluciones avanzadas de inteligencia artificial. Con su tecnología Repo Grokking™, Zencoder analiza a fondo toda su base de código, descubriendo patrones estructurales, lógica arquitectónica e implementaciones personalizadas.
Además, con la compatibilidad universal de herramientas, puede traer su propia CLI, incluyendo Claude Code, OpenAI Codex o GoogleGemini, directamente a su IDE con contexto completo. También ofrece inteligencia multi-repo, lo que permite a Zencoder comprender bases de código a escala empresarial, conexiones de servicios y propagación de dependencias.
Estas son algunas de las principales características de Zencoder:
1️⃣ Integraciones - Se integra a la perfección con más de 20 entornos de desarrollo, lo que simplifica todo el ciclo de vida del desarrollo. Esto convierte a Zencoder en el único agente de codificación de IA que ofrece este amplio nivel de integración.
4️⃣ Asistente de codificación de IA todo en uno - Acelere su flujo de trabajo de desarrollo con una solución de IA integrada que proporciona completado de código inteligente, generación automática de código y revisiones de código en tiempo real.
- Completado de código: las sugerencias de código inteligentes mantienen el ritmo con completados precisos y sensibles al contexto que reducen los errores y mejoran la productividad.
- Generación de código: produce código limpio, coherente y listo para la producción, adaptado a las necesidades de su proyecto y perfectamente alineado con sus estándares de codificación.
- Agente de revisión de código: la revisión continua del código garantiza que cada línea cumple las mejores prácticas, detecta posibles errores y mejora la seguridad mediante comentarios precisos y procesables.
- Asistente de Chat - Reciba respuestas instantáneas y fiables y soporte de codificación personalizado. Manténgase productivo con recomendaciones inteligentes que mantienen su flujo de trabajo fluido y eficiente.
3️⃣ Triple seguridad - Zencoder es el único agente de codificación de IA con certificación SOC 2 Tipo II, ISO 27001 & ISO 42001.
5️⃣ Zentester - Zentester utiliza la IA para automatizar las pruebas a todos los niveles, de modo que su equipo pueda detectar errores con antelación y enviar código de alta calidad con mayor rapidez. Sólo tiene que describir lo que desea probar en un inglés sencillo y Zentester se encargará del resto, adaptándose a medida que evoluciona su código.
Vea Zentester en acción:
Esto es lo que hace:
- Nuestros agentes inteligentes comprenden tu aplicación e interactúan de forma natural en las capas de interfaz de usuario, API y base de datos.
- A medida que su código cambia, Zentester adapta automáticamente sus pruebas, eliminando la necesidad de reescribir constantemente.
- Desde las funciones unitarias hasta los flujos de usuario integrales, cada capa de su aplicación se prueba exhaustivamente a escala.
- La IA de Zentester identifica rutas de código peligrosas, descubre casos extremos ocultos y crea pruebas basadas en cómo interactúan los usuarios reales con su aplicación.
6️⃣ Agentes Zen - Los Agentes Zen son compañeros de equipo de IA totalmente personalizables que entienden su código, se integran perfectamente con sus herramientas existentes y pueden desplegarse en segundos.

Con los Agentes Zen, usted puede:
- Construir de forma más inteligente - Crea agentes especializados para tareas como revisiones de pull requests, pruebas o refactorización, adaptados a tu arquitectura y frameworks.
- Integración rápida - Conéctese a herramientas como Jira, GitHub y Stripe en cuestión de minutos utilizando nuestra interfaz MCP sin código, para que sus agentes se ejecuten directamente en sus flujos de trabajo existentes.
- Despliegue instantáneo - Despliegue agentes en toda su organización con un solo clic, con actualizaciones automáticas y acceso compartido para mantener los equipos alineados y la experiencia escalable.
- Explore el mercado: explore una creciente biblioteca de agentes de código abierto prediseñados, listos para integrarse en su flujo de trabajo, o contribuya con los suyos para ayudar a la comunidad a avanzar más rápidamente.
Empiece a utilizar Zencoder de forma gratuita y convierta cualquier LLM en un agente de codificación listo para la producción.



