
Con i modelli linguistici di grandi dimensioni (LLM) che stanno rapidamente diventando una parte essenziale dello sviluppo del software moderno, una recente ricerca indica che oltre la metà degli sviluppatori senior (53%) ritiene che questi strumenti siano già in grado di codificare in modo più efficace della maggior parte degli esseri umani. Questi modelli vengono utilizzati quotidianamente per il debug di errori complicati, la generazione di funzioni più pulite e la revisione del codice, risparmiando ore di lavoro agli sviluppatori. Ma con il rapido rilascio di nuovi LLM, non è sempre facile capire quali valga la pena adottare. Ecco perché abbiamo creato un elenco dei 6 migliori LLM per la codifica che possono aiutarvi a codificare in modo più intelligente, a risparmiare tempo e ad aumentare la vostra produttività.

I 6 migliori LLM per il coding da considerare nel 2026
Prima di approfondire le nostre scelte, ecco cosa vi aspetta:
|
Modello |
Migliore per |
Precisione |
Ragionamento |
Finestra di contesto |
Costo |
Supporto dell'ecosistema |
Disponibilità Open-Source |
|
GPT-5 (OpenAI) |
Migliore in assoluto |
74,9% (SWE-bench) / 88% (Aider Polyglot) |
Ragionamento in più fasi, flussi di lavoro collaborativi |
400K token (272K input + 128K output) |
Piani gratuiti e a pagamento a partire da 20 dollari al mese |
Molto forte (plugin, strumenti, integrazione con gli sviluppatori) |
Chiuso |
|
Claude 4 Sonnet (Antropico) |
Debug complesso |
72,7% (SWE-bench verificato) |
Debugging avanzato, pianificazione, follow-up delle istruzioni |
128K gettoni |
Piani gratuiti e a pagamento a partire da 17 dollari al mese |
Ecosistema in crescita con integrazioni di strumenti |
Chiuso |
|
Gemini 2.5 Pro (Google) |
Basi di codice di grandi dimensioni e stack completo |
SWE-bench verificato: ~63,8% (codifica agenziale); LiveCodeBench: ~70,4%; Aider Polyglot: ~74,0%. |
Ragionamento controllato ("Deep Think"), flussi di lavoro in più fasi |
1.000.000 di gettoni |
1,25 dollari per milione di input + 10 dollari per milione di output |
Forte (strumento Google e integrazione API) |
Chiuso |
|
DeepSeek V3.1 / R1 |
Miglior valore (Open-Source) |
Corrisponde ai vecchi modelli OpenAI, si avvicina a Gemini nel ragionamento |
Logica e auto-riflessione sintonizzate su RL |
128K gettoni |
Input: $0,07-0,56/M, Output: $1.68-2.19/M |
Medio (adozione open-source, flessibilità per gli sviluppatori) |
Aperto (licenza MIT) |
|
Llama 4 (Meta: Scout / Maverick) |
Open-Source (contesto ampio) |
Ottime prestazioni di codifica e ragionamento in benchmark di modelli aperti |
Buon ragionamento passo-passo (meno avanzato di GPT-5/Claude) |
Fino a 10 milioni di gettoni (Scout) |
$0,15-0,50/M in ingresso, $0,50-0,85/M in uscita |
Ecosistema open-source in crescita, strumenti per gli sviluppatori |
Pesi aperti |
|
Claude Sonnet 4.5 (Anthropic) |
Debug collaborativo e compiti a lungo termine |
Stimato ~75-77% (classe SWE-bench) |
Ragionamento agenziale ibrido, uso autonomo di strumenti e pianificazione |
200K gettoni |
3$/M input + 15$/M output |
Espansione dell'ecosistema antropico con toolchain agenziali |
Chiuso |
1. Il migliore in assoluto: GPT-5 di OpenAI
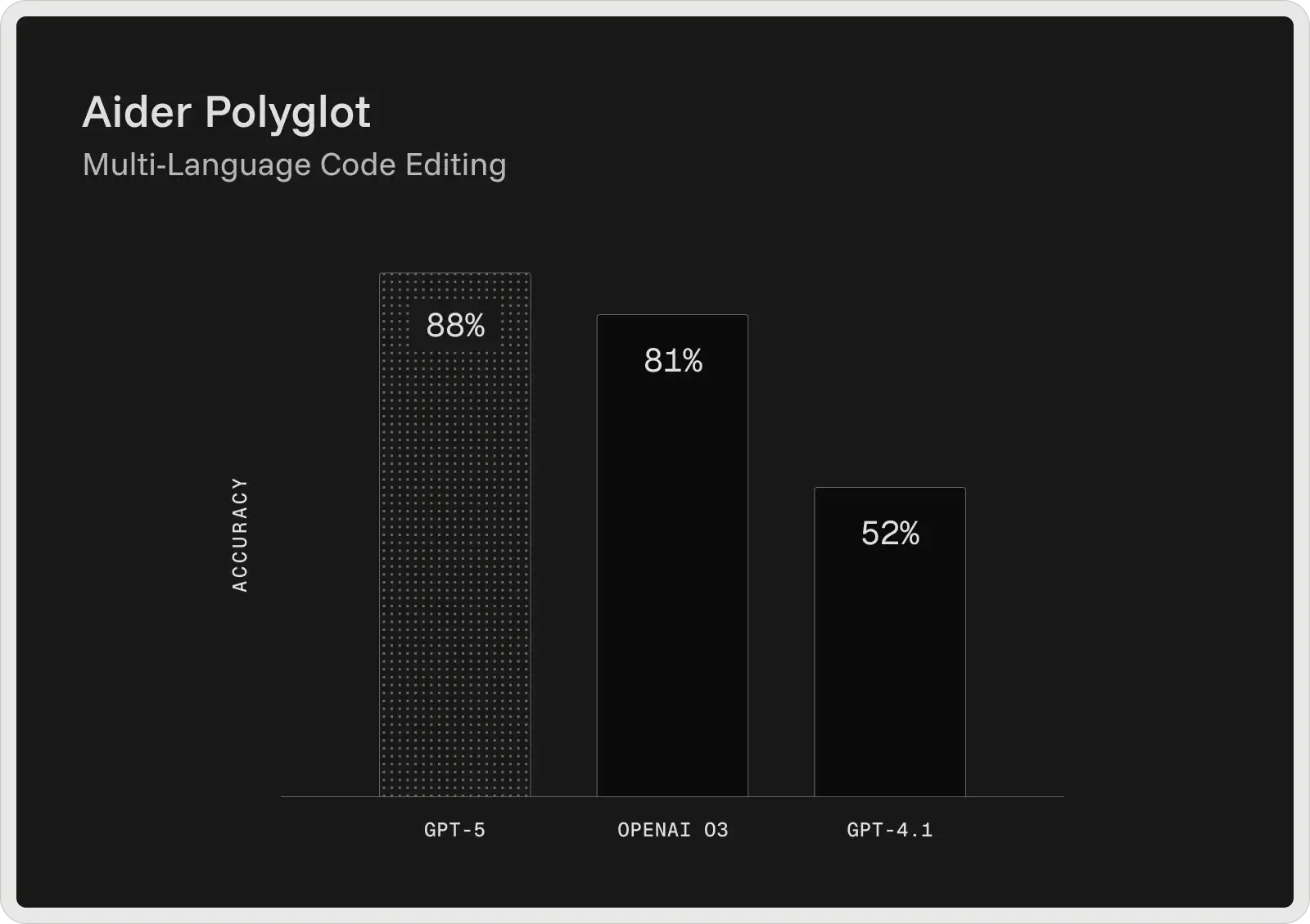
GPT-5 di OpenAI è attualmente il modello di codifica più forte della sua linea, in grado di fornire i migliori risultati nei più diffusi benchmark per sviluppatori. Sullo SWE-bench Verified raggiunge il 74,9% di accuratezza e su Aider Polyglot l'88%, riducendo i tassi di errore rispetto ai modelli precedenti, come GPT-4.1 e o3. Progettato come assistente di codifica collaborativo, GPT-5 è in grado di generare e modificare codice, correggere bug e rispondere a domande complesse su grandi basi di codice con coerenza.
Fornisce spiegazioni prima e tra un passaggio e l'altro, segue istruzioni dettagliate in modo affidabile e può eseguire attività di codifica in più fasi senza perdere di vista il contesto. Nei test interni è stato preferito anche per lo sviluppo di frontend, dove gli sviluppatori hanno preferito i suoi risultati a quelli di o3 circa il 70% delle volte.
Capacità principali:
- Finestra di contesto da 400K token - Gestisce 272K token di input + 128K di output, consentendo l'analisi su scala di repository, l'inserimento di documentazione e il ragionamento su più file.
- Rilevamento e debug avanzato dei bug - Identifica problemi profondamente nascosti in grandi basi di codice e fornisce correzioni convalidate con motivazioni chiare.
- Integrazione e concatenamento di strumenti - Richiama strumenti esterni in modo affidabile, supportando flussi di lavoro sequenziali e paralleli con un minor numero di errori.
- Fedeltà delle istruzioni - Aderisce strettamente ai suggerimenti dettagliati degli sviluppatori, anche in attività in più fasi o altamente vincolate.
- Flussi di lavoro collaborativi - Condivide piani, fasi intermedie e aggiornamenti sui progressi durante le sessioni di codifica di lunga durata.
- Ragionamento a lungo termine - Mantiene la coerenza in progetti di grandi dimensioni, preservando le dipendenze e la logica su centinaia di migliaia di token.
- Recupero affidabile dei contenuti - Ottime prestazioni su benchmark di recupero di contesti lunghi (ad esempio, OpenAI-MRCR, BrowseComp), che gli consentono di individuare e utilizzare informazioni nascoste in input molto grandi.
Pro e contro:
🟢 Pro:
- Gestisce in modo più efficace i compiti di codifica più lunghi e le grandi basi di codice.
- Segue istruzioni dettagliate con maggiore precisione.
- Individua bug sottili che spesso sfuggono ad altri modelli.
- Produce risposte più pulite e meno "allucinate" in alcuni casi.
🔴 Contro:
- Fatica a implementare completamente piani complessi e in più fasi.
- A volte ha allucinazioni o lascia il codice incompleto.
- Velocità di risposta ridotta e qualità di output incoerente.
- Il codice generato può essere troppo sicuro di sé ma fragile.
Prezzi
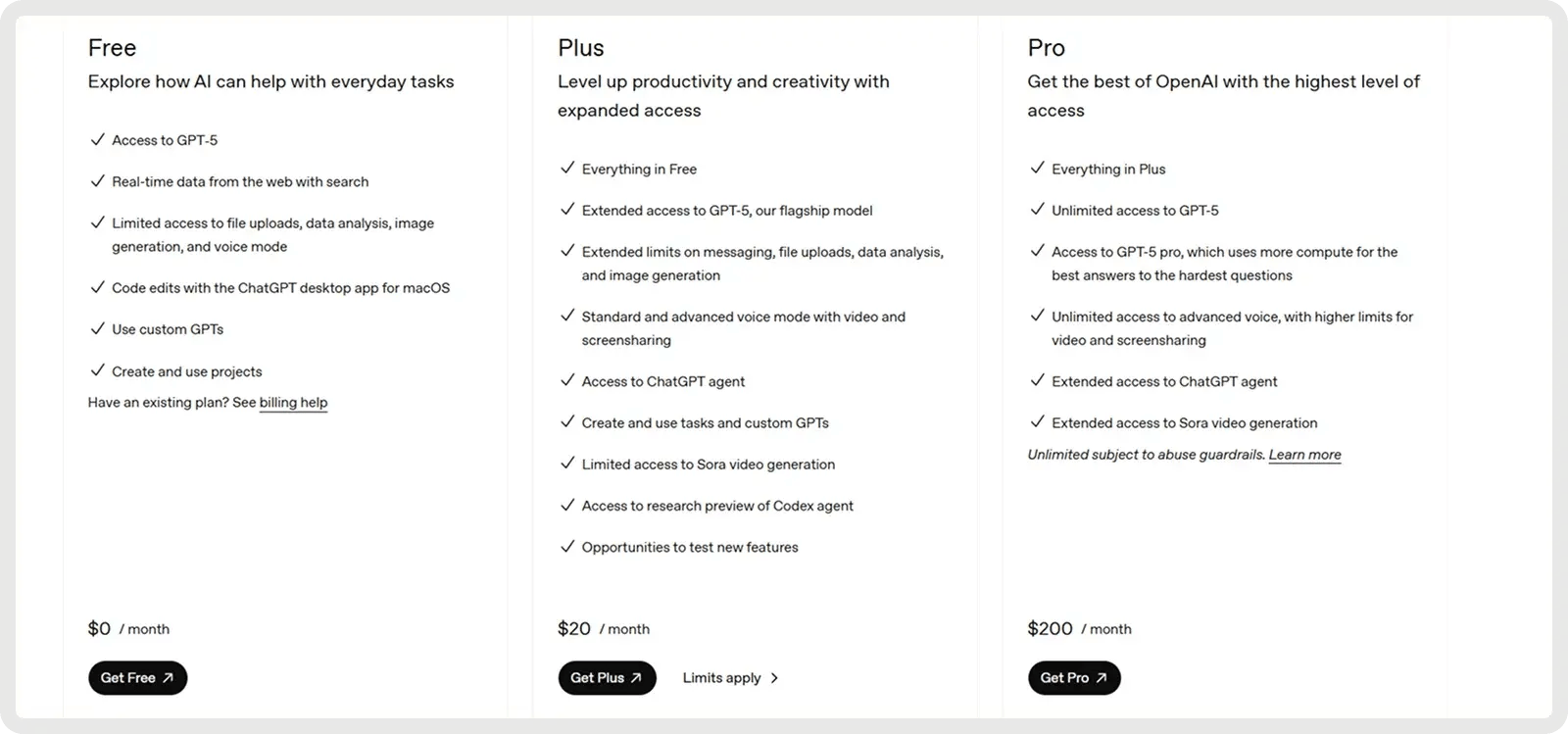
GPT-5 di OpenAI offre un piano gratuito e due piani a pagamento a partire da 20 dollari al mese.
2. Il migliore per il debug complesso: Anthropic Claude 4 (Sonnet 4)
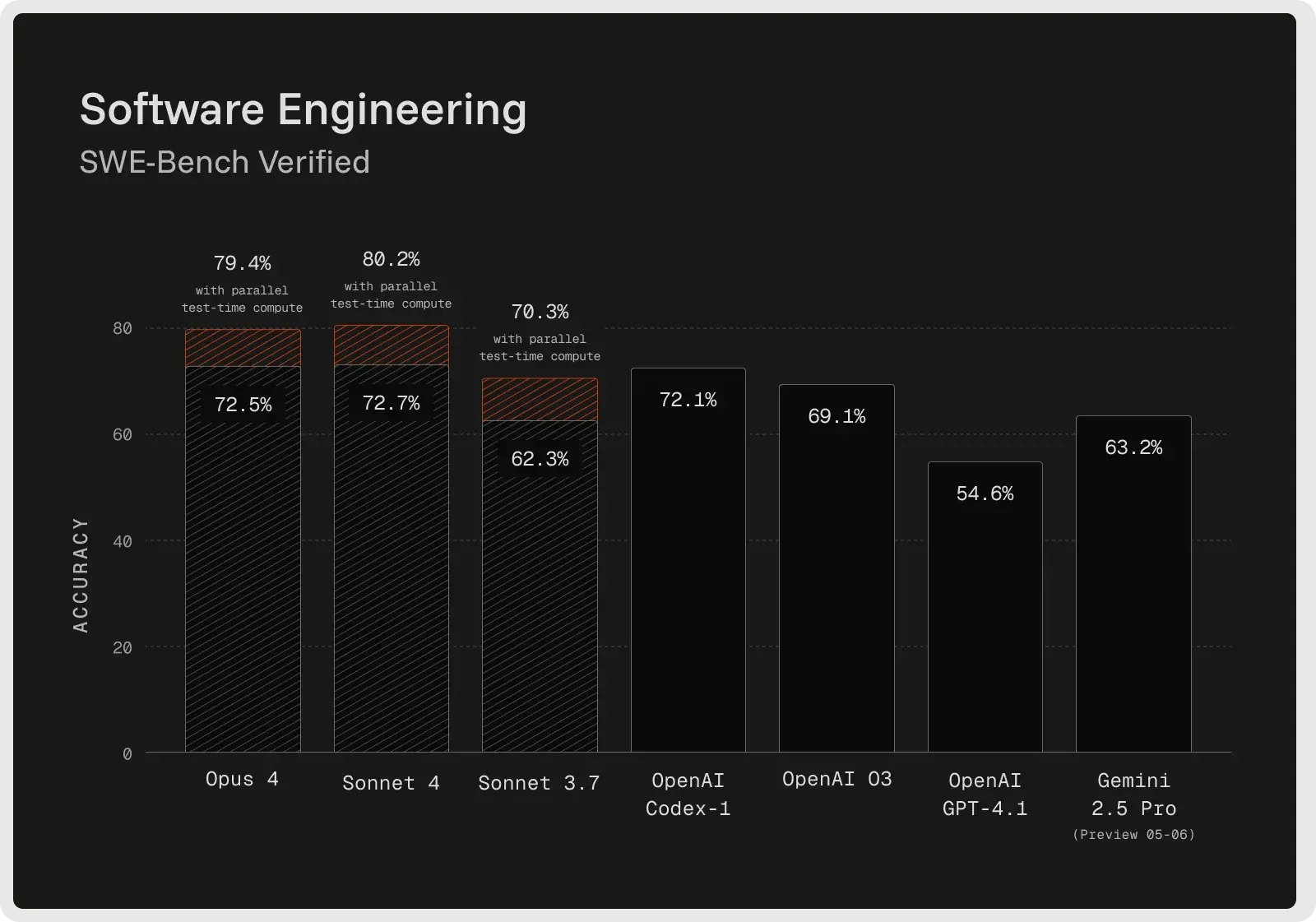
Claude Sonnet 4 è costruito per il ragionamento avanzato e ha ottime prestazioni nel debugging complesso e nella revisione del codice. Il modello spesso delinea un piano prima di apportare modifiche, il che migliora la chiarezza e aiuta a individuare i problemi prima del processo. Nel benchmark SWE-Bench Verified ha ottenuto un'accuratezza del 72,7% sulle correzioni di bug reali, stabilendo un nuovo record e superando la maggior parte dei concorrenti. La modalità di riflessione estesa consente fino a 128K token, permettendo di elaborare grandi basi di codice e documenti di supporto e riducendo le allucinazioni grazie a domande chiarificatrici. Gli sviluppatori riferiscono di un minor numero di errori, di una gestione più affidabile delle richieste ambigue e di correzioni incrementali più sicure rispetto agli approcci one-shot.
Funzionalità chiave:
- Sviluppo dell'intero ciclo di vita - Supporta l'intero processo, dalla pianificazione e progettazione al refactoring, al debugging e alla manutenzione a lungo termine.
- Seguire le istruzioni e utilizzare gli strumenti - Seleziona e integra strumenti esterni (ad esempio, API di file, esecuzione di codice) nei flussi di lavoro secondo le necessità.
- Individuazione degli errori e debugging - Identifica, spiega e risolve i bug con una chiara motivazione per le modifiche al codice.
- Refactoring e trasformazione del codice - Esegue ristrutturazioni su larga scala di file o intere basi di codice.
- Generazione e pianificazione di precisione - Produce codice pulito e strutturato, allineato con gli obiettivi del progetto e della progettazione.
- Ragionamento in contesti lunghi - Mantiene la coerenza in contesti estesi per codebase di grandi dimensioni o documenti lunghi.
- Aderenza alla logica affidabile - Evita le scorciatoie più fragili e segue la logica prevista con maggiore coerenza.
Pro e contro:
🟢 Pro:
- È in grado di generare e completare compiti di codifica di grandi dimensioni.
- Segue le istruzioni in modo più affidabile rispetto alle versioni precedenti.
- Costo equilibrato rispetto alle prestazioni di Opus.
- Fornisce output di codice chiari e ben strutturati.
🔴 Contro:
- Può fraintendere richieste semplici o fornire spiegazioni eccessive.
- È più debole nelle attività di OCR e di codifica di documenti pesanti.
- Ha difficoltà a risolvere problemi molto complessi e in più fasi.
- La coerenza dell'output può variare a seconda dei settori di codifica.
Prezzi
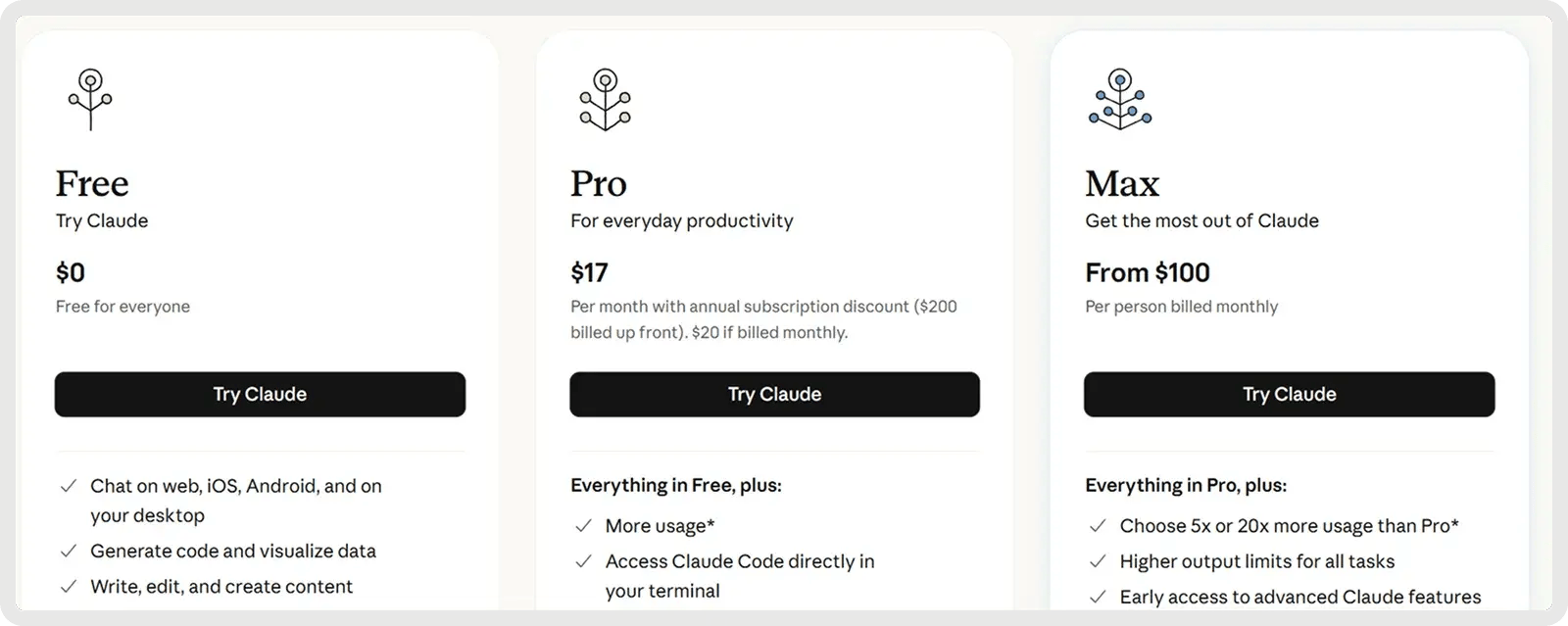
Claude offre un piano gratuito e 2 piani a pagamento a partire da 17 dollari al mese.
3. Il migliore per Codebase di grandi dimensioni e Full Stack: Google Gemini 2.5 Pro
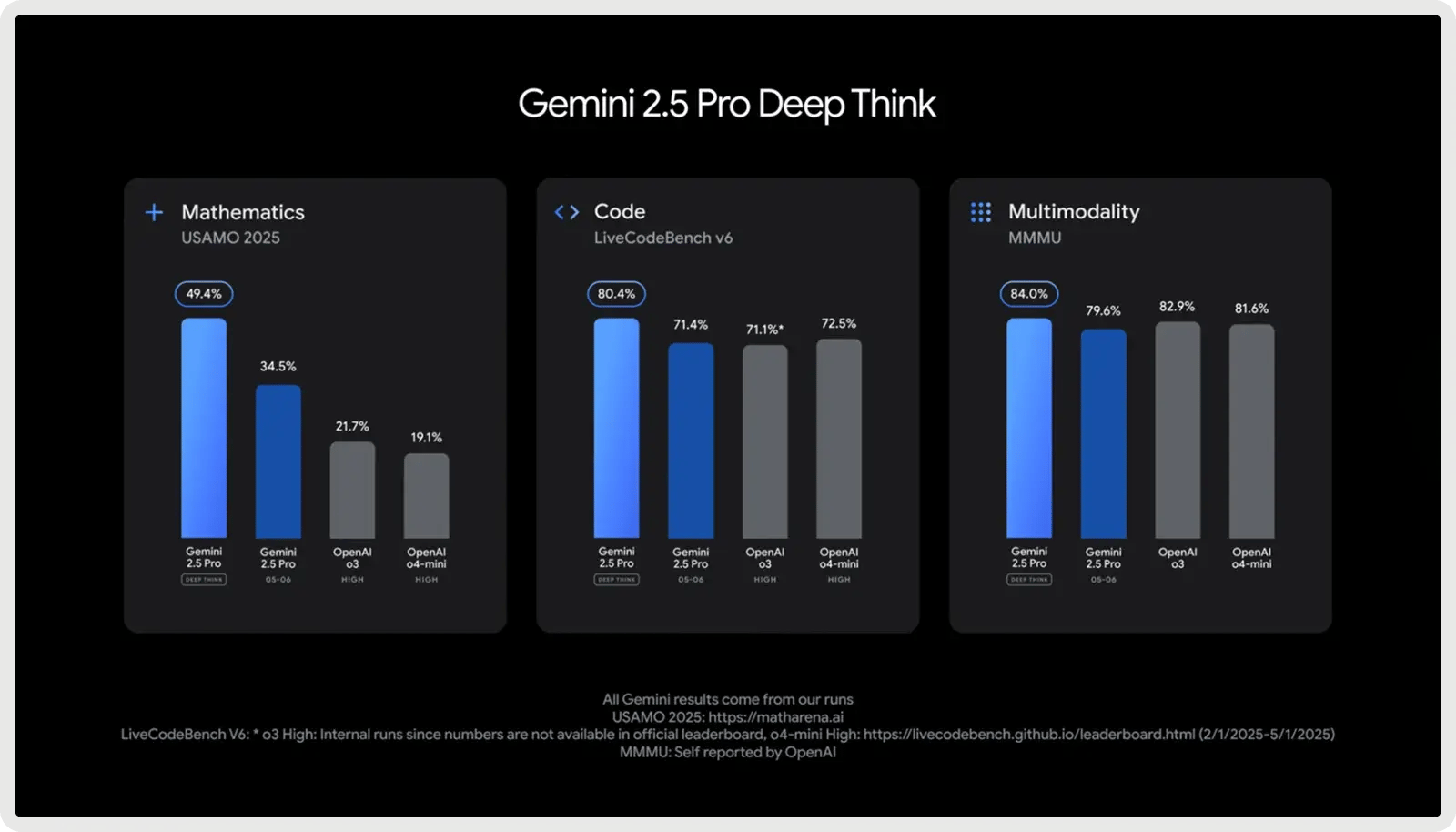
Google Gemini 2.5 Pro è progettato per progetti di codifica su larga scala, con una finestra contestuale da 1.000.000 token che gli consente di gestire interi repository, suite di test e script di migrazione in un unico passaggio. È ottimizzato per lo sviluppo di software, eccellendo nella generazione, nel debug e nel refactoring di codice su più file e framework. Supporta flussi di lavoro di codifica complessi, dalla gestione delle dipendenze tra più file al ragionamento sulle query di database e sulle integrazioni API. Grazie alle risposte rapide e alla consapevolezza dell'intero stack, aiuta gli sviluppatori a scrivere, analizzare e integrare il codice tra i livelli frontend, backend e dati senza soluzione di continuità.
Funzionalità chiave:
- Generazione di codice - Crea nuove funzioni, moduli o intere applicazioni a partire da richieste o specifiche.
- Modifica del codice - Applica correzioni, miglioramenti o refactoring mirati direttamente nelle basi di codice esistenti.
- Ragionamento in più fasi - Suddivide compiti di programmazione complessi in fasi logiche e li esegue in modo affidabile.
- Sviluppo di frontend/UI - Costruisce componenti web interattivi, layout e stili a partire da un linguaggio naturale o da progetti.
- Gestione di grandi basi di codice - Comprende e naviga in interi repository con dipendenze da più file.
- Integrazione MCP - Supporta il Model Context Protocol per l'utilizzo senza problemi di strumenti di codifica open-source.
- Ragionamento controllabile - Regola la profondità di risoluzione dei problemi ("modalità di pensiero") per bilanciare precisione, velocità e costi.
Pro e contro:
🟢 Pro:
- Eccelle nella generazione di soluzioni complete da zero.
- Gestisce codebase di grandi dimensioni con contesti da 1M di token.
- Ottime prestazioni di benchmark nei compiti di codifica.
- Deep Think potenzia il ragionamento per problemi complessi.
🔴 Contro:
- Più debole nel debugging e nella correzione del codice.
- A volte ha le allucinazioni o modifica il codice senza chiedere.
- Uscite prolisse e incoerenze di formato.
- Affidabilità mista rispetto alle versioni precedenti.
Prezzi
Google Gemini 2.5 Pro offre un piano gratuito e un piano a pagamento a partire da 1,25 dollari per milione di token in ingresso e 10 dollari per milione di token in uscita. Si applicano tariffe aggiuntive per richieste superiori a 200k token, oltre a tariffe opzionali per il caching e la messa a terra.
4. Miglior valore (Open-Source): DeepSeek V3.1/R1

I modelli V3.1 e R1 di DeepSeek offrono un forte valore per gli sviluppatori che cercano sia la convenienza che la flessibilità dell'open-source. Questi modelli Mixture-of-Experts, concessi in licenza MIT, sono specificamente ottimizzati per compiti matematici e di codifica. Il modello R1 è stato perfezionato con l'apprendimento per rinforzo per il ragionamento e la logica avanzati, dimostrando prestazioni pari o superiori a quelle dei vecchi modelli OpenAI e avvicinandosi a Gemini 2.5 Pro nei benchmark di ragionamento complessi.
Funzionalità chiave:
- Efficienza della miscela di esperti - Attiva solo un sottoinsieme di esperti per ogni interrogazione, offrendo una capacità elevata e mantenendo i costi di inferenza più bassi rispetto ai modelli densi.
- Apprendimento rinforzato per il ragionamento (R1) - Ottimizzato con RL per migliorare il ragionamento a catena, l'inferenza logica e l'accuratezza dei passaggi.
- Prestazioni matematiche e logiche avanzate - Ottimi risultati su benchmark come MATH e AIME, che lo rendono particolarmente valido nel ragionamento simbolico e nella risoluzione di problemi.
- Autocertificazione e riflessione - Genera catene di ragionamento interne e può autoverificare le risposte, migliorando l'affidabilità in compiti complessi e in più fasi.
- Licenza open-source e MIT - La licenza completamente permissiva consente l'ispezione, la modifica e l'uso commerciale illimitato, a differenza di molti LLM proprietari.
- Scalabilità e opzioni di implementazione - Supporta la quantizzazione e le varianti distillate, consentendo l'uso su hardware più piccolo con una perdita minima di prestazioni.
- Supporto multilingue - È addestrato in più lingue (tra cui inglese e cinese), consentendo una più ampia applicabilità per gli sviluppatori di tutto il mondo.
Pro e contro:
🟢 Pro:
- Genera soluzioni complete e funzionali con elevata affidabilità.
- Supporta codebase di grandi dimensioni con un contesto esteso a 128k.
- La modalità "Think" migliora il ragionamento per compiti di programmazione complessi.
- Modello a peso aperto con costi operativi ridotti.
🔴 Contro:
- Precisione limitata nel seguire istruzioni di codifica dettagliate.
- Risultati prolissi, in particolare nella modalità di ragionamento.
- Tracce di modelli leader nella qualità del codice.
- Potenziali rischi di sicurezza e allineamento nel codice generato.
Prezzi
La versione V3.1 è un modello economico e generico, con token di input al prezzo di 0,07 dollari per 1 milione (cache hit) o 0,56 dollari per 1 milione (cache miss) e token di output a 1,68 dollari per 1 milione. Questo lo rende molto interessante per i casi di utilizzo ad alto volume, soprattutto quando la cache è efficace.
R1, posizionato come modello di ragionamento premium, costa circa 0,14 dollari per milione di token di input e circa 2,19 dollari per milione di token di output.
5. Miglior Open-Source (Large Context): Meta Llama 4
I nuovi modelli aperti di Meta, Llama 4 Scout e Maverick (rilasciati nell'aprile 2025), ampliano notevolmente la lunghezza del contesto, con Scout (17B parametri) che supporta fino a 10 milioni di token e gestisce input multimodali. Scout dimostra miglioramenti significativi nella codifica, ottenendo una maggiore precisione su benchmark come MBPP e dimostrando una migliore gestione di compiti di programmazione lunghi e multi-file rispetto a Llama 3. Gli sviluppatori possono utilizzare Scout per gestire attività di codifica complesse, come il refactor di più file, il tracciamento delle dipendenze o l'analisi del sistema end-to-end, senza che il modello "dimentichi" il contesto precedente. Poiché è open-source e commercialmente utilizzabile, i team possono perfezionarlo per i propri flussi di lavoro ed eseguirlo in modo sicuro sull'hardware locale.
Funzionalità chiave:
- Generazione di codice - Produce codice accurato e funzionale per un'ampia gamma di attività di programmazione.
- Codifica interattiva - Supporta il completamento del codice in tempo reale, la modifica e l'assistenza al debug.
- Chiamata di funzioni - Genera output strutturati (ad esempio, JSON) per chiamare API o integrarsi con strumenti esterni.
- Gestione del codice su larga scala - Gestisce interi repository o progetti multi-file senza perdere il contesto, grazie alla finestra da 10 milioni di token.
- Seguire le istruzioni - Si adatta con precisione alle richieste specifiche del codice per attività come la correzione di bug, il refactoring o la progettazione di algoritmi.
- Distribuzione efficiente - Funziona efficacemente su hardware locale, rendendo più accessibile l'assistenza alla codifica su larga scala.
- Ragionamento del codice - Comprende le dipendenze e la semantica all'interno delle basi di codice, supportando analisi più approfondite e approfondimenti a livello di sistema.
Pro e contro:
🟢 Pro:
- Inferenza veloce, pratica per l'uso locale della codifica.
- Punteggi di codifica competitivi tra i modelli aperti.
- Gestisce finestre di codice/contesto molto lunghe.
- Peso aperto e personalizzabile per uso privato.
🔴 Contro:
- Non è all'altezza dei modelli migliori (GPT-5, Claude) per quanto riguarda l'accuratezza della codifica.
- Incoerente o difettoso nei casi limite di codifica.
- Lo stile di output può sembrare secco o sintetico.
- Feedback di adozione limitato.
Prezzi
I prezzi di Llama 4 si aggirano attualmente intorno a 0,15$/M di input e 0,50$/M di output per Scout, e 0,22-0,27$/M di input e 0,85$/M di output per Maverick, con lievi variazioni a seconda del fornitore.
6. Il migliore per il debug collaborativo e i compiti a lungo termine: Claude Sonnet 4.5
Claude Sonnet 4.5 è il modello di ragionamento ibrido più recente e più capace di Anthropic, che amplia Sonnet 4 con un'intelligenza più acuta, una generazione di codice più rapida e una migliore coordinazione agenziale. È dotato di una finestra di contesto da 200K token, di una maggiore precisione nell'uso degli strumenti e di conoscenze di dominio perfezionate nei settori della codifica, della finanza e della sicurezza informatica. Ottimizzato per il ragionamento esteso e la collaborazione su larga scala, eccelle nella gestione di progetti di codifica complessi, agenti autonomi e attività analitiche di lunga durata.
Funzionalità chiave:
- Generazione di codice end-to-end - Gestisce l'intero ciclo di vita dello sviluppo del software, dalla pianificazione e implementazione al debug, al refactoring e alla manutenzione.
- Ragionamento avanzato - Esegue analisi logiche in più fasi e segue istruzioni complesse per risolvere sfide di programmazione sofisticate.
- Correzione automatica degli errori - Rileva, spiega e risolve i problemi del codice in tempo reale per migliorare l'affidabilità e ridurre il lavoro di debug.
- Finestra di contesto estesa - Supporta fino a 64K token per comprendere grandi basi di codice, documenti di progettazione e dipendenze a livello di progetto senza perdere il contesto.
- Integrazione autonoma degli strumenti - Seleziona e gestisce gli strumenti di sviluppo appropriati, come compilatori, interpreti e sistemi di controllo delle versioni, per semplificare i flussi di lavoro.
- Cybersecurity proattiva - Identifica, attenua e corregge autonomamente le vulnerabilità per mantenere le basi di codice sicure e resistenti.
- Funzionamento persistente dell'agente - Esegue attività di codifica di lunga durata e gestisce flussi di lavoro in più fasi in modo continuo attraverso le sessioni.
Pro e contro:
🟢 Pro:
- Forte capacità di ragionamento e precisione di codifica tra le attività.
- Eccellente conservazione del contesto e consapevolezza dei file multipli.
- Uso efficiente degli strumenti e risoluzione strutturata dei problemi.
- Capace di sessioni di codifica più lunghe e autonome.
🔴 Contro:
- Risposte più lente durante il ragionamento profondo o la pianificazione.
- Occasioni di deriva delle istruzioni ed errori fattuali.
- Finestra contestuale ancora limitata per progetti molto grandi.
- Difficoltà con gli ambienti interattivi.
Prezzi
I prezzi di Sonnet 4.5 partono da 3 dollari per milione di token di input e 15 dollari per milione di token di output.

Dai modelli ai flussi di lavoro: Rendere pratici gli LLM con Zencoder
Ora che conoscete i 6 migliori LLM per la codifica, la domanda successiva è come metterli effettivamente al lavoro nello sviluppo quotidiano. Anche i modelli più avanzati richiedono un sistema adeguato per integrarsi con i vostri strumenti, automatizzare i flussi di lavoro e fornire risultati coerenti su progetti di grandi dimensioni.
È qui che entra in gioco Zencoder! Vi permette di inserire il vostro modello (o i vostri modelli) preferito in un agente di codifica di livello produttivo che ottimizza i flussi di lavoro, gestisce l'integrazione e garantisce l'affidabilità su scala.
Cos'è Zencoder

Zencoder è un agente di codifica dotato di intelligenza artificiale che migliora il ciclo di vita dello sviluppo del software (SDLC) migliorando la produttività, la precisione e la creatività grazie a soluzioni avanzate di intelligenza artificiale. Grazie alla tecnologia Repo Grokking™, Zencoder analizza a fondo l'intera base di codice, scoprendo modelli strutturali, logica architettonica e implementazioni personalizzate.
Inoltre, grazie alla compatibilità con gli strumenti universali, è possibile portare la propria CLI, tra cui Claude Code, OpenAI Codex o GoogleGemini, direttamente nell'IDE con un contesto completo. Zencoder offre anche un'intelligenza multi-repo, che gli consente di comprendere codebase su scala aziendale, connessioni di servizi e propagazione delle dipendenze.
Ecco alcune delle caratteristiche principali di Zencoder:
1️⃣ Integrazioni - Si integra perfettamente con oltre 20 ambienti di sviluppo, semplificando l'intero ciclo di vita dello sviluppo. Zencoder è l'unico agente di codifica dell'intelligenza artificiale che offre un livello di integrazione così ampio.
4️⃣ All-in-One AI Coding Assistant - Accelera il flusso di lavoro di sviluppo con una soluzione AI integrata che fornisce completamento intelligente del codice, generazione automatica del codice e revisione del codice in tempo reale.
- Completamento del codice - I suggerimenti intelligenti per il codice mantengono lo slancio grazie a completamenti precisi e consapevoli del contesto che riducono gli errori e migliorano la produttività.
- Generazione del codice - Produce codice pulito, coerente e pronto per la produzione, adattato alle esigenze del progetto e perfettamente in linea con gli standard di codifica.
- Code Review Agent - La revisione continua del codice assicura che ogni riga sia conforme alle best practice, catturi potenziali bug e migliori la sicurezza grazie a un feedback preciso e perseguibile.
- Assistente di chat - Riceverete risposte immediate e affidabili e un supporto personalizzato per la codifica. Rimanete produttivi con consigli intelligenti che mantengono il vostro flusso di lavoro fluido ed efficiente.
3️⃣ Security treble - Zencoder è l'unico agente di codifica AI con certificazione SOC 2 Type II, ISO 27001 e ISO 42001.
5️⃣ Zentester - Zentester utilizza l'intelligenza artificiale per automatizzare i test a ogni livello, in modo che il team possa individuare tempestivamente i bug e distribuire più rapidamente codice di alta qualità. È sufficiente descrivere ciò che si desidera testare in un linguaggio semplice e Zentester si occuperà del resto, adattandosi all'evoluzione del codice.
Guardate Zentester in azione:
Ecco cosa fa:
- I nostri agenti intelligenti comprendono la vostra applicazione e interagiscono in modo naturale tra i livelli UI, API e database.
- Quando il codice cambia, Zentester adatta automaticamente i test, eliminando la necessità di una costante riscrittura.
- Dalle funzioni unitarie ai flussi utente end-to-end, ogni livello della vostra applicazione viene testato a fondo su scala.
- L'intelligenza artificiale di Zentester identifica i percorsi di codice rischiosi, scopre i casi limite nascosti e crea test basati sul modo in cui gli utenti reali interagiscono con la vostra applicazione.
6️⃣ Zen Agents - Gli Zen Agents sono compagni di intelligenza artificiale completamente personalizzabili che comprendono il vostro codice, si integrano perfettamente con gli strumenti esistenti e possono essere distribuiti in pochi secondi.

Con gli Zen Agents, potete:
- Costruire in modo più intelligente - Creare agenti specializzati per attività come la revisione delle richieste di pull, i test o il refactoring, su misura per la vostra architettura e i vostri framework.
- Integrarsi rapidamente - Collegarsi a strumenti come Jira, GitHub e Stripe in pochi minuti utilizzando la nostra interfaccia MCP senza codice, in modo che i vostri agenti funzionino all'interno dei vostri flussi di lavoro esistenti.
- Distribuzione immediata - Distribuite gli agenti in tutta l'organizzazione con un solo clic, con aggiornamenti automatici e accesso condiviso per mantenere i team allineati e le competenze scalabili.
- Esplorate il mercato - Sfogliate una libreria crescente di agenti open-source pre-costruiti, pronti per essere inseriti nel vostro flusso di lavoro, o contribuite con i vostri per aiutare la comunità a muoversi più velocemente.
Iniziate gratuitamente con Zencoder e trasformate qualsiasi LLM in un agente di codifica pronto per la produzione!



