
Com os modelos de linguagem ampla (LLMs) se tornando rapidamente uma parte essencial do desenvolvimento de software moderno, uma pesquisa recente indica que mais da metade dos desenvolvedores seniores (53%) acredita que essas ferramentas já podem codificar com mais eficiência do que a maioria dos humanos. Esses modelos são usados diariamente para depurar erros complicados, gerar funções mais limpas e revisar códigos, economizando horas de trabalho dos desenvolvedores. Porém, com novos LLMs sendo lançados em um ritmo acelerado, nem sempre é fácil saber quais valem a pena adotar. Por isso, criamos uma lista dos 6 melhores LLMs para codificação que podem ajudá-lo a codificar de forma mais inteligente, economizar tempo e aumentar sua produtividade.

6 melhores LLMs para codificação a serem considerados em 2026
Antes de nos aprofundarmos em nossas principais escolhas, eis o que espera por você:
|
Modelo |
Melhor para |
Precisão |
Raciocínio |
Janela de contexto |
Custo |
Suporte do ecossistema |
Disponibilidade de código aberto |
|
GPT-5 (OpenAI) |
Melhor geral |
74,9% (SWE-bench) / 88% (Aider Polyglot) |
Raciocínio em várias etapas, fluxos de trabalho colaborativos |
400 mil tokens (272 mil de entrada + 128 mil de saída) |
Grátis + planos pagos a partir de US$ 20/mês |
Muito forte (plug-ins, ferramentas, integração de desenvolvimento) |
Fechado |
|
Claude 4 Sonnet (Antrópico) |
Depuração complexa |
72,7% (SWE-bench verificado) |
Depuração avançada, planejamento, acompanhamento de instruções |
128K tokens |
Planos gratuitos e pagos a partir de US$ 17/mês |
Ecossistema em crescimento com integrações de ferramentas |
Fechado |
|
Gemini 2.5 Pro (Google) |
Grandes bases de código e pilha completa |
SWE-bench verificado: ~63,8% (codificação agêntica); LiveCodeBench: ~70,4%; Aider Polyglot: ~74,0% |
Raciocínio controlado ("Deep Think"), fluxos de trabalho de várias etapas |
1.000.000 de tokens |
US$ 1,25 por milhão de entrada + US$ 10 por milhão de saída |
Forte (ferramenta do Google e integração de API) |
Fechado |
|
DeepSeek V3.1 / R1 |
Melhor valor (código aberto) |
Corresponde aos modelos mais antigos da OpenAI, aproxima-se do Gemini em termos de raciocínio |
Lógica ajustada por RL e autorreflexão |
128K tokens |
Entrada: US$ 0,07-0,56/M, Saída: $1.68-2.19/M |
Médio (adoção de código aberto, flexibilidade do desenvolvedor) |
Aberto (licença MIT) |
|
Llama 4 (Meta: Scout / Maverick) |
Código aberto (contexto amplo) |
Forte desempenho de codificação e raciocínio em benchmarks de modelo aberto |
Bom raciocínio passo a passo (menos avançado que o GPT-5/Claude) |
Até 10 milhões de tokens (Scout) |
US$ 0,15-0,50/M de entrada, US$ 0,50-0,85/M de saída |
Crescente ecossistema de código aberto, ferramentas para desenvolvedores |
Pesos abertos |
|
Claude Sonnet 4.5 (Anthropic) |
Depuração colaborativa e tarefas de contexto longo |
Estimativa de ~75-77% (classe SWE-bench) |
Raciocínio agêntico híbrido, uso de ferramentas autônomas e planejamento |
200 mil tokens |
US$ 3/M de entrada + US$ 15/M de saída |
Expansão do ecossistema Anthropic com cadeias de ferramentas agênticas |
Fechado |
1. Melhor geral: GPT-5 da OpenAI
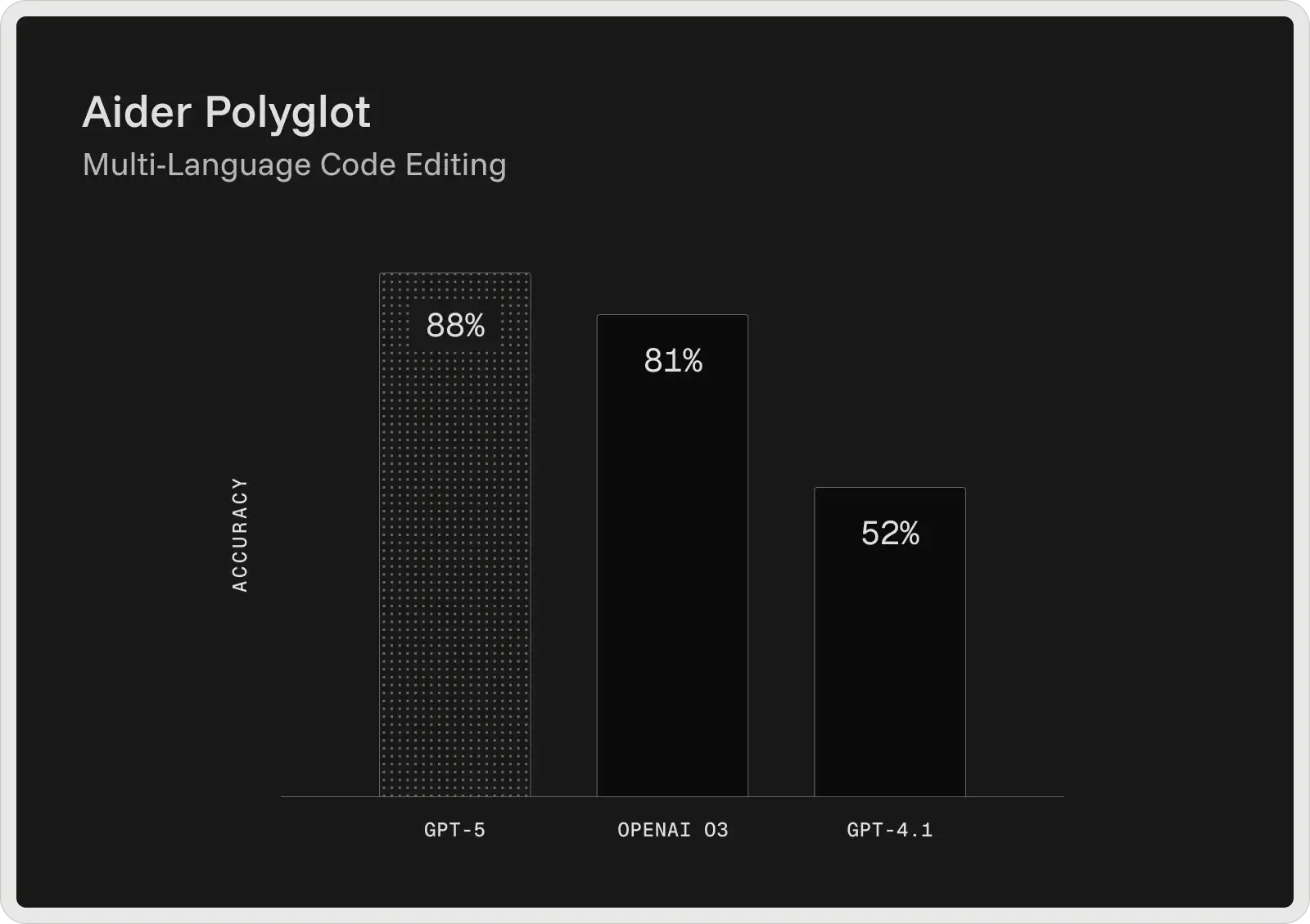
O GPT-5 da OpenAI é atualmente o modelo de codificação mais forte de sua linha, fornecendo os melhores resultados em benchmarks de desenvolvedores amplamente utilizados. No SWE-bench Verified, ele alcança 74,9% de precisão e, no Aider Polyglot, obtém 88% de pontuação, reduzindo as taxas de erro em comparação com modelos anteriores, como o GPT-4.1 e o3. Projetado como um assistente de codificação colaborativo, o GPT-5 pode gerar e editar códigos, corrigir bugs e responder a perguntas complexas sobre grandes bases de código com consistência.
Ele fornece explicações antes e entre as etapas, segue instruções detalhadas de forma confiável e pode executar tarefas de codificação em vários estágios sem perder o controle do contexto. Nos testes internos, ele também foi o preferido para o desenvolvimento de front-end, em que os desenvolvedores preferiram seus resultados aos do o3 em cerca de 70% das vezes.
Principais recursos:
- Janela de contexto de 400 mil tokens - lida com 272 mil tokens de entrada e 128 mil de saída, permitindo análise em escala de repositório, ingestão de documentação e raciocínio de vários arquivos.
- Detecção e depuração avançadas de bugs - Identifica problemas profundamente ocultos em grandes bases de código e fornece correções validadas com raciocínio claro.
- Integração e encadeamento de ferramentas - Chama ferramentas externas de forma confiável, suportando fluxos de trabalho sequenciais e paralelos com menos falhas.
- Fidelidade das instruções - Segue à risca as instruções detalhadas do desenvolvedor, mesmo em tarefas de várias etapas ou altamente restritas.
- Fluxos de trabalho colaborativos - Compartilha planos, etapas intermediárias e atualizações de progresso durante sessões de codificação de longa duração.
- Raciocínio de contexto longo - Mantém a coerência em grandes projetos, preservando dependências e lógica em centenas de milhares de tokens.
- Recuperação confiável de conteúdo - desempenho sólido em benchmarks de recuperação de contexto longo (por exemplo, OpenAI-MRCR, BrowseComp), o que permite localizar e usar informações ocultas em entradas muito grandes.
Prós e contras:
🟢 Prós :
- Lida com tarefas de codificação mais longas e grandes bases de código com mais eficiência.
- Segue instruções detalhadas com maior precisão.
- Detecta erros sutis que outros modelos geralmente deixam passar.
- Produz respostas mais limpas e menos "alucinadas" em alguns casos.
- Tem dificuldade para implementar totalmente planos complexos e de várias etapas.
- Às vezes, alucina ou deixa o código incompleto.
- Velocidade de resposta mais lenta e qualidade de saída inconsistente.
- O código gerado pode ser muito confiante, mas frágil.
Preços
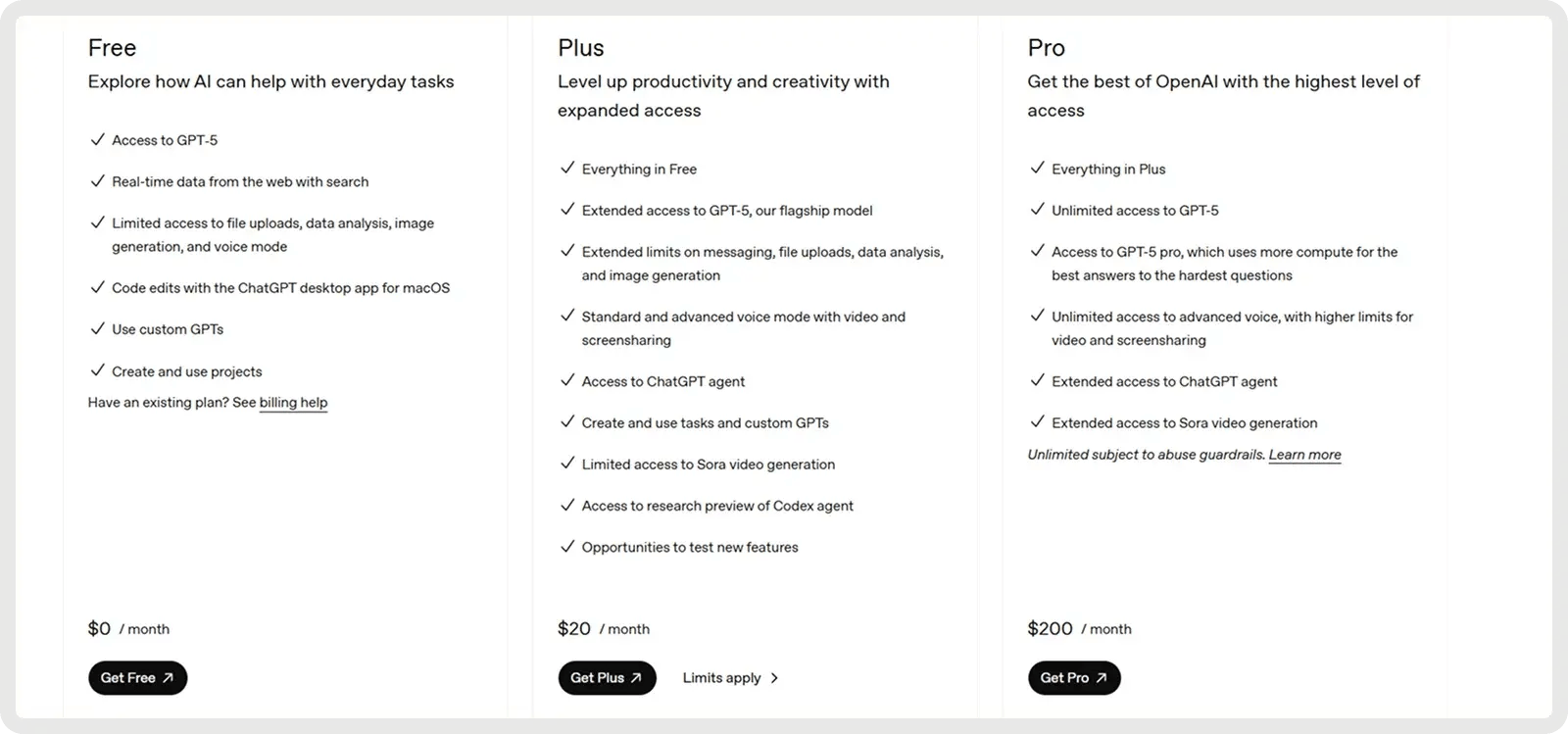
O GPT-5 da OpenAI oferece um plano gratuito e dois planos pagos a partir de US$ 20 por mês.
2. Melhor para depuração complexa: Anthropic Claude 4 (Soneto 4)
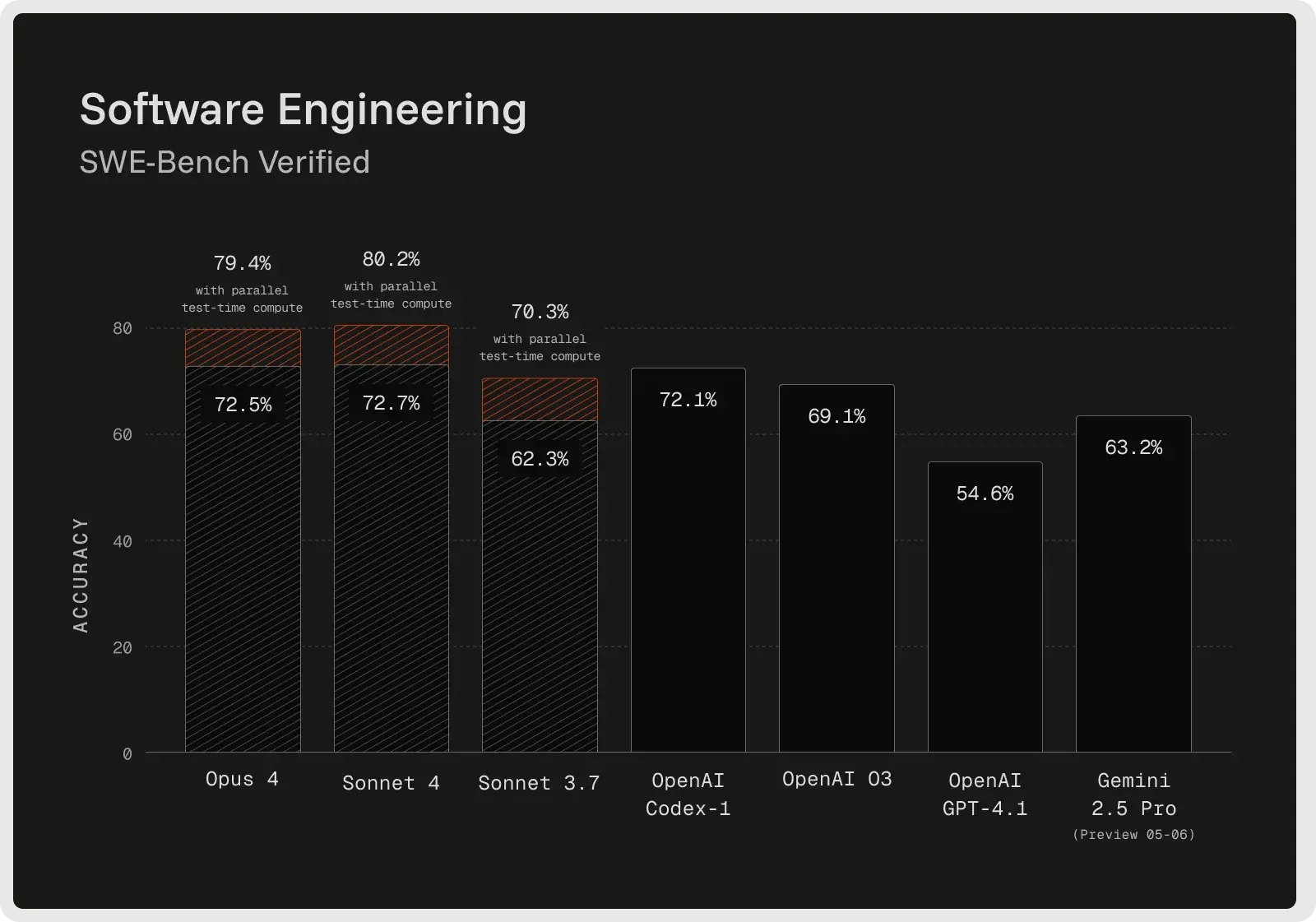
O Claude Sonnet 4 foi desenvolvido para raciocínio avançado e tem um ótimo desempenho em depuração complexa e revisão de código. O modelo geralmente delineia um plano antes de fazer edições, o que melhora a clareza e ajuda a detectar problemas no início do processo. No benchmark SWE-Bench Verified, ele atingiu 72,7% de precisão nas correções de bugs do mundo real, estabelecendo um novo recorde e superando a maioria dos concorrentes. Seu modo de raciocínio estendido permite até 128 mil tokens, possibilitando o processamento de grandes bases de código e documentos de apoio, reduzindo as alucinações por meio de perguntas esclarecedoras. Os desenvolvedores relatam menos erros, tratamento mais confiável de solicitações ambíguas e correções incrementais mais seguras em comparação com abordagens únicas.
Principais recursos:
- Desenvolvimento de ciclo de vida completo - Oferece suporte a todo o processo, desde o planejamento e o design até a refatoração, a depuração e a manutenção de longo prazo.
- Seguimento de instruções e uso de ferramentas - Seleciona e integra ferramentas externas (por exemplo, APIs de arquivos, execução de código) em fluxos de trabalho, conforme necessário.
- Detecção e depuração de erros - Identifica, explica e resolve bugs com raciocínio claro para edições de código.
- Refatoração e transformação de código - Realiza reestruturação em larga escala em arquivos ou bases de código inteiras.
- Geração de precisão e planejamento - Produz código limpo e estruturado alinhado com o design e as metas do projeto.
- Raciocínio de contexto longo - Mantém a coerência em contextos estendidos para grandes bases de código ou documentos extensos.
- Aderência lógica confiável - Evita atalhos frágeis e segue a lógica pretendida com maior consistência.
Prós e contras:
🟢 Prós :
- Forte na geração e conclusão de tarefas de codificação maiores.
- Segue as instruções de forma mais confiável do que as versões anteriores.
- Equilíbrio entre custo e desempenho em comparação com o Opus.
- Fornece saídas de código claras e bem estruturadas.
- Pode não entender solicitações simples ou explicar demais.
- Fraco em OCR e em tarefas de codificação com muitos documentos.
- Tem dificuldade para resolver problemas muito complexos e de várias etapas.
- A consistência da saída pode variar entre os domínios de codificação.
Preços
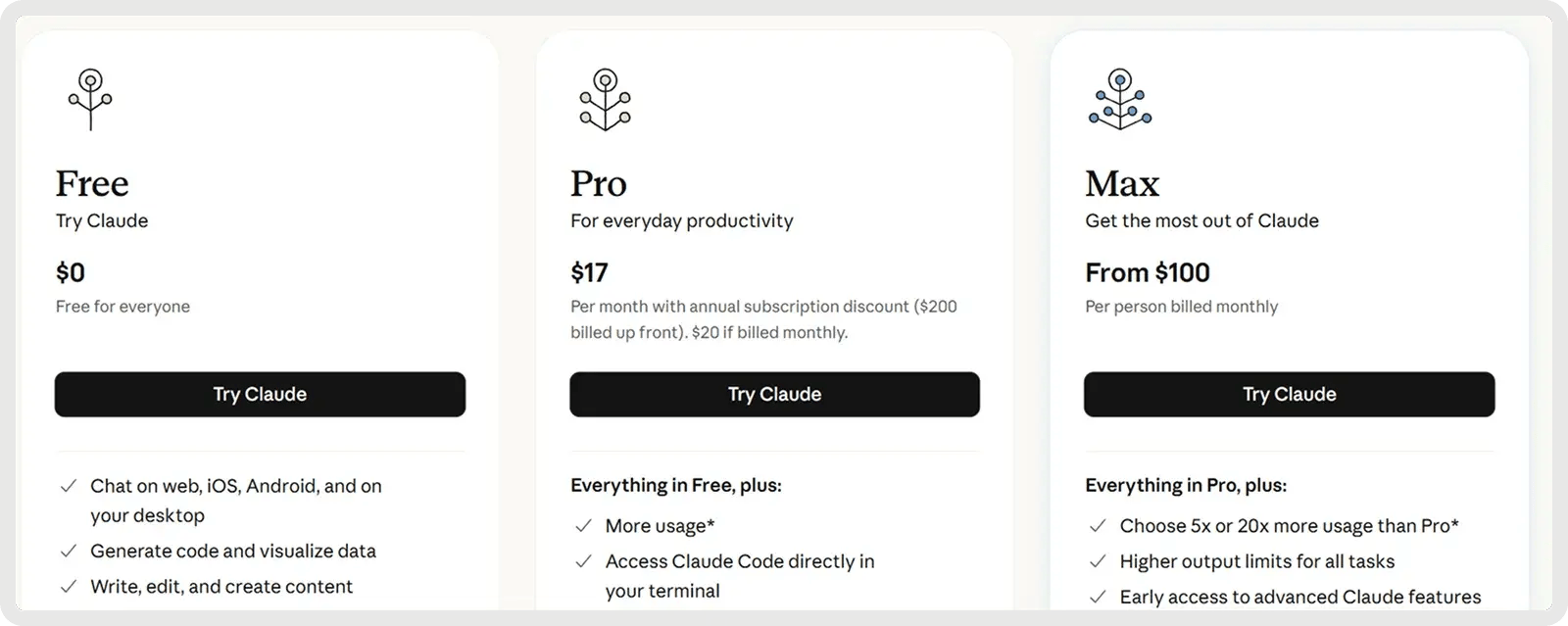
O Claude oferece um plano gratuito e dois planos pagos a partir de US$ 17 por mês.
3. Melhor para grandes bases de código e pilha completa: Google Gemini 2.5 Pro
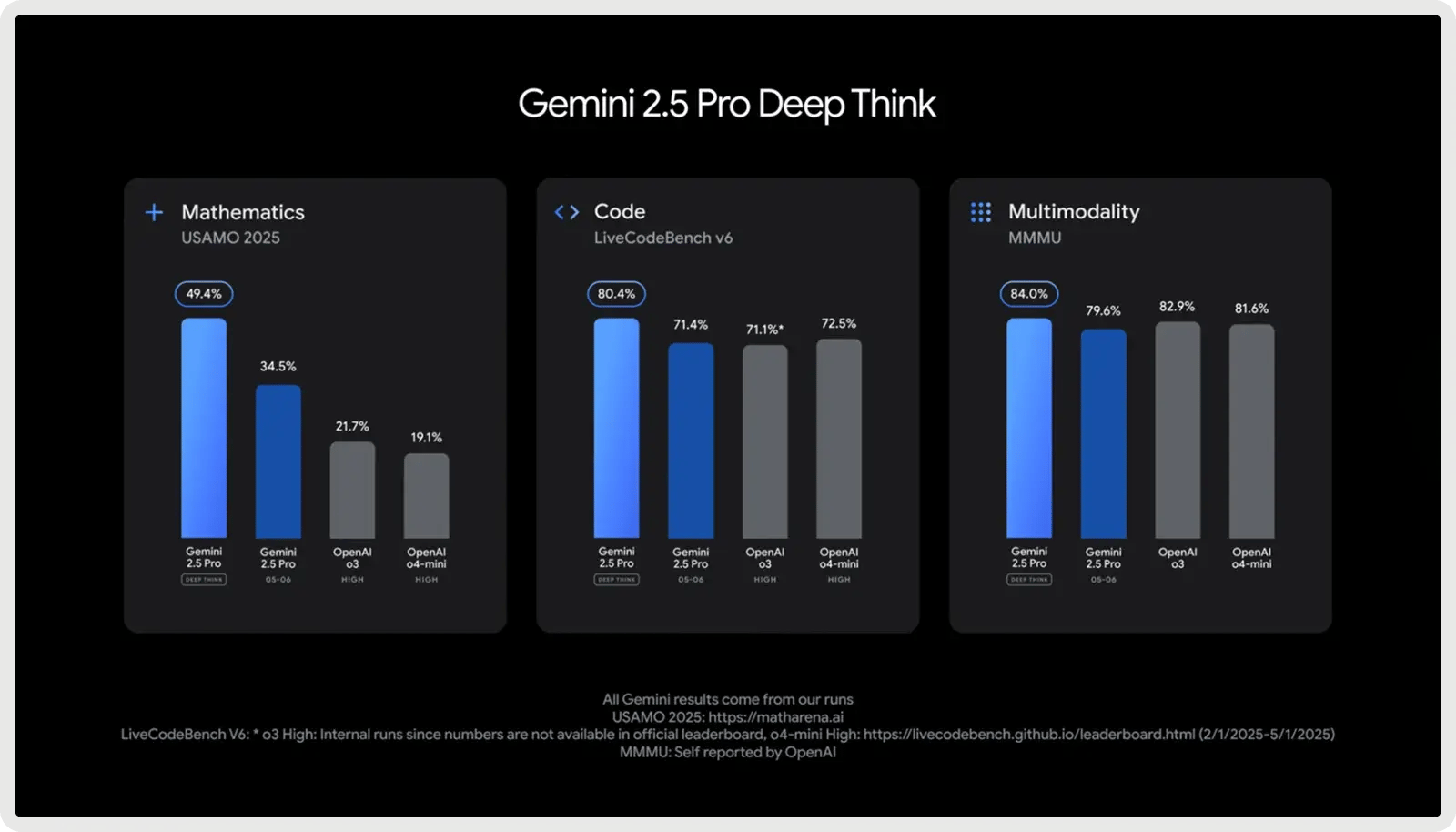
O Google Gemini 2.5 Pro foi projetado para projetos de codificação em grande escala, apresentando uma janela de contexto de 1.000.000 de tokens que permite lidar com repositórios inteiros, conjuntos de testes e scripts de migração em uma única passagem. Ele é otimizado para o desenvolvimento de software, destacando-se na geração, depuração e refatoração de código em vários arquivos e estruturas. É compatível com fluxos de trabalho de codificação complexos, desde a manipulação de dependências de vários arquivos até o raciocínio sobre consultas a bancos de dados e integrações de API. Com respostas rápidas e conscientização de pilha completa, ele ajuda os desenvolvedores a escrever, analisar e integrar códigos nas camadas de front-end, back-end e dados sem problemas.
Principais recursos:
- Geração de código - Cria novas funções, módulos ou aplicativos inteiros a partir de prompts ou especificações.
- Edição de código - Aplica correções, melhorias ou refatorações direcionadas diretamente nas bases de código existentes.
- Raciocínio em várias etapas - Divide tarefas de programação complexas em etapas lógicas e as executa de forma confiável.
- Desenvolvimento de front-end/UI - Cria componentes interativos da Web, layouts e estilos a partir de linguagem natural ou projetos.
- Manuseio de grandes bases de código - Compreende e navega em repositórios inteiros com dependências de vários arquivos.
- Integração com MCP - Oferece suporte ao protocolo de contexto de modelo para uso contínuo de ferramentas de codificação de código aberto.
- Raciocínio controlável - Ajusta a profundidade da solução de problemas ("modo de pensar") para equilibrar precisão, velocidade e custo.
Prós e contras:
🟢 Prós:
- Excelente na geração de soluções completas a partir do zero.
- Lida com grandes bases de código com contexto de 1 milhão de tokens.
- Forte desempenho de benchmark em tarefas de codificação.
- O Deep Think aumenta o raciocínio para problemas complexos.
- Fraco em depuração e correções de código.
- Às vezes, tem alucinações ou altera o código sem ser solicitado.
- Saídas detalhadas e inconsistências de formato.
- Confiabilidade mista em comparação com as versões anteriores.
Preços
O Google Gemini 2.5 Pro oferece um plano gratuito e um plano pago a partir de US$ 1,25 por milhão de tokens de entrada e US$ 10 por milhão de tokens de saída. Taxas adicionais se aplicam a prompts que excedam 200 mil tokens, juntamente com taxas opcionais de cache e aterramento.
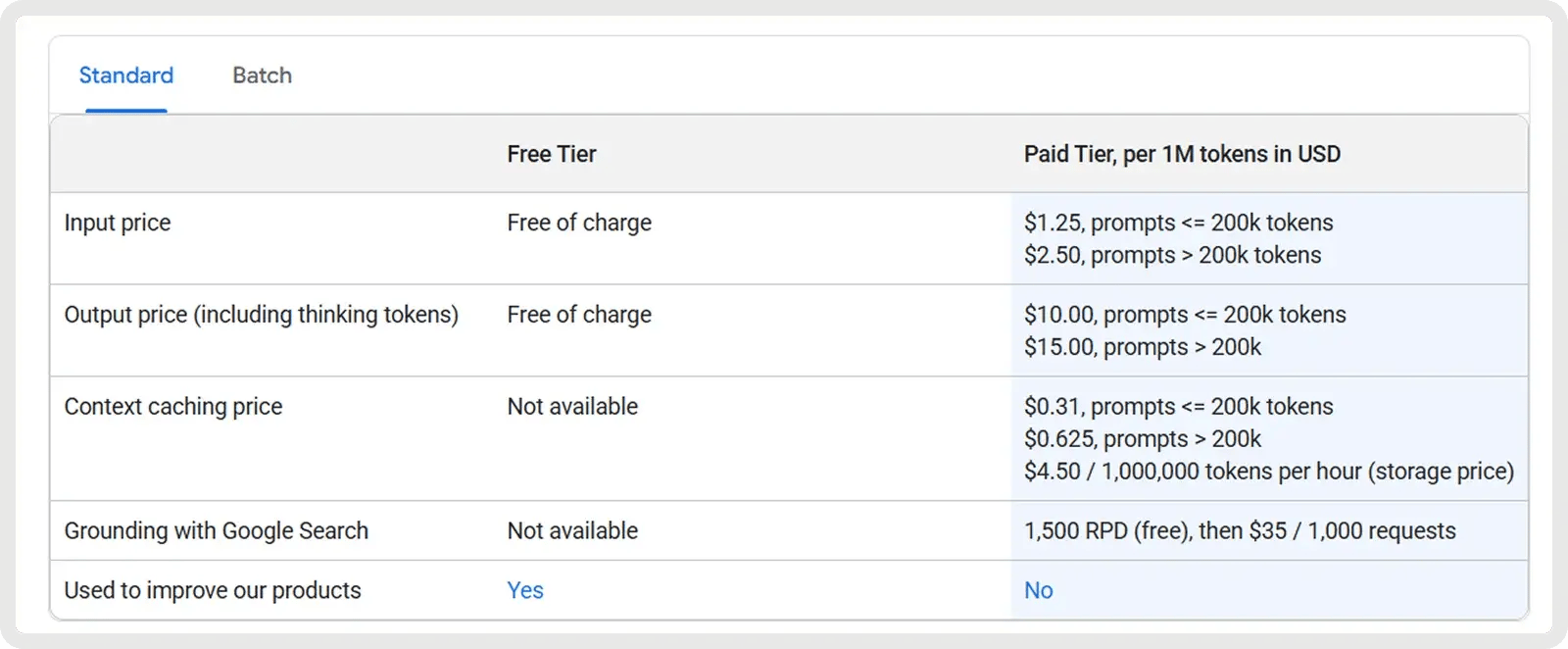
4. Melhor valor (código aberto): DeepSeek V3.1/R1

Os modelos V3.1 e R1 do DeepSeek oferecem um grande valor para os desenvolvedores que buscam acessibilidade e flexibilidade de código aberto. Esses modelos Mixture-of-Experts, licenciados sob a licença MIT, são especificamente otimizados para tarefas matemáticas e de codificação. O modelo R1 é ajustado com aprendizado de reforço para raciocínio e lógica avançados, demonstrando um desempenho que iguala ou excede o dos modelos OpenAI mais antigos e se aproxima do Gemini 2.5 Pro em benchmarks de raciocínio complexos.
Principais recursos:
- Eficiência de combinação de especialistas - Ativa apenas um subconjunto de especialistas por consulta, oferecendo alta capacidade e mantendo os custos de inferência mais baixos do que os modelos densos.
- Aprendizado de reforço para raciocínio (R1) - Ajustado com RL para melhorar o raciocínio de cadeia de pensamento, a inferência lógica e a precisão passo a passo.
- Desempenho avançado em matemática e lógica - Resultados sólidos em benchmarks como MATH e AIME, tornando-o especialmente bom em raciocínio simbólico e solução de problemas.
- Autocertificação e reflexão - Gera cadeias internas de raciocínio e pode autocertificar respostas, aumentando a confiabilidade em tarefas complexas e de várias etapas.
- Código aberto e licença MIT - A licença totalmente permissiva permite inspeção, modificação e uso comercial irrestrito, ao contrário da maioria dos LLMs proprietários.
- Escalabilidade e opções de implementação - Suporta quantização e variantes destiladas, permitindo o uso em hardware menor com perda mínima de desempenho.
- Suporte multilíngue - treinado em vários idiomas (incluindo inglês e chinês), permitindo uma aplicabilidade mais ampla para desenvolvedores globais.
Prós e contras:
🟢 Prós:
- Gera soluções completas e funcionais com alta confiabilidade.
- Oferece suporte a grandes bases de código com um contexto estendido de 128k.
- O modo "Think" aprimora o raciocínio para tarefas de programação complexas.
- Modelo de peso aberto com custos operacionais mais baixos.
- Precisão limitada ao seguir instruções detalhadas de codificação.
- Saídas detalhadas, principalmente no modo de raciocínio.
- Trilhas de modelos líderes em qualidade de código.
- Possíveis riscos de segurança e alinhamento no código gerado.
Preços
O V3.1 é um modelo econômico e de uso geral, com tokens de entrada a US$ 0,07 por 1 milhão (acerto de cache) ou US$ 0,56 por 1 milhão (falha de cache) e tokens de saída aUS$ 1,68 por 1 milhão. Isso o torna altamente atraente para casos de uso de alto volume, especialmente quando o cache é eficaz.
O R1, posicionado como um modelo de raciocínio premium, custa aproximadamente US$ 0,14 por milhão de tokens de entrada e cerca de US$ 2,19 por milhão de tokens de saída.
5. Melhor código aberto (contexto grande): Meta Llama 4
Os mais novos modelos abertos da Meta, Llama 4 Scout e Maverick (lançados em abril de 2025), expandem drasticamente o comprimento do contexto, com o Scout (parâmetros de 17B) suportando até 10 milhões de tokens e lidando com entrada multimodal. O Scout demonstra melhorias significativas na codificação, alcançando maior precisão em benchmarks como o MBPP e demonstrando melhor manuseio de tarefas de programação longas e com vários arquivos em comparação com o Llama 3. Os desenvolvedores podem usar o Scout para gerenciar tarefas de codificação complexas, como refatorações de vários arquivos, rastreamento de dependências ou análise de sistema de ponta a ponta, sem que o modelo "esqueça" o contexto anterior. Por ser de código aberto e comercialmente utilizável, as equipes podem ajustá-lo para seus próprios fluxos de trabalho e executá-lo com segurança no hardware local.
Principais recursos:
- Geração de código - Produz código preciso e funcional em uma ampla gama de tarefas de programação.
- Codificação interativa - Oferece suporte ao preenchimento de código em tempo real, edição e assistência à depuração.
- Chamada de função - Gera saídas estruturadas (por exemplo, JSON) para chamar APIs ou integrar-se a ferramentas externas.
- Manuseio de código em grande escala - Gerencia repositórios inteiros ou projetos com vários arquivos sem perder o contexto, graças à sua janela de 10 milhões de tokens.
- Seguimento de instruções - Adapta-se precisamente a solicitações específicas de codificação para tarefas como correções de bugs, refatoração ou design de algoritmos.
- Implementação eficiente - É executado com eficiência em hardware local, tornando mais acessível a assistência à codificação em larga escala.
- Raciocínio de código - Compreende dependências e semântica em bases de código, oferecendo suporte a análises mais profundas e percepções em nível de sistema.
Prós e contras:
🟢 Prós :
- Inferência rápida, prática para uso de codificação local.
- Pontuações de codificação competitivas entre os modelos abertos.
- Lida com janelas de código/contexto muito longas.
- Aberto e personalizável para uso privado.
- Fica atrás dos principais modelos (GPT-5, Claude) em termos de precisão de codificação.
- Inconsistente ou com erros em tarefas de codificação de casos extremos.
- O estilo de saída pode parecer seco ou sintético.
- Feedback de adoção limitado.
Preço
O preço do Llama 4 está atualmente em torno de US$ 0,15/M de entrada e US$ 0,50/M de tokens de saída para o Scout, e US$ 0,22-0,27/M de entrada e US$ 0,85/M de tokens de saída para o Maverick, variando ligeiramente de acordo com o fornecedor.
6. Melhor para depuração colaborativa e tarefas de contexto longo: Claude Sonnet 4.5
O Claude Sonnet 4.5 é o modelo de raciocínio híbrido mais recente e mais capaz da Anthropic, expandindo o Sonnet 4 com inteligência mais nítida, geração de código mais rápida e coordenação agêntica aprimorada. Ele apresenta uma janela de contexto de 200 mil tokens, maior precisão no uso de ferramentas e conhecimento de domínio refinado em codificação, finanças e segurança cibernética. Otimizado para raciocínio estendido e colaboração em larga escala, ele se destaca no gerenciamento de projetos de codificação complexos, agentes autônomos e tarefas analíticas de longo prazo.
Principais recursos:
- Geração de código de ponta a ponta - lida com todo o ciclo de vida do desenvolvimento de software, desde o planejamento e a implementação até a depuração, a refatoração e a manutenção.
- Raciocínio avançado - Executa análise lógica em várias etapas e segue instruções complexas para resolver desafios sofisticados de programação.
- Correção automatizada de erros - Detecta, explica e corrige problemas de código em tempo real para aumentar a confiabilidade e reduzir o esforço de depuração.
- Janela de contexto estendida - Suporta até 64 mil tokens para compreender grandes bases de código, documentos de design e dependências de todo o projeto sem perder o contexto.
- Integração autônoma de ferramentas - Seleciona e opera ferramentas de desenvolvimento apropriadas, como compiladores, interpretadores e sistemas de controle de versão, para fluxos de trabalho simplificados.
- Segurança cibernética proativa - Identifica, atenua e corrige vulnerabilidades de forma autônoma para manter bases de código seguras e resilientes.
- Operação persistente do agente - executa tarefas de codificação de longa duração e gerencia fluxos de trabalho de vários estágios continuamente em todas as sessões.
Prós e contras:
Prós:
- Raciocínio sólido e precisão de codificação em todas as tarefas.
- Excelente retenção de contexto e reconhecimento de vários arquivos.
- Uso eficiente de ferramentas e solução estruturada de problemas.
- Capaz de sessões de codificação mais longas e autônomas.
- Respostas mais lentas durante o raciocínio ou planejamento profundo.
- Ocasionalmente, desvio de instruções e erros factuais.
- Janela de contexto ainda limitada para projetos muito grandes.
- Problemas com ambientes interativos
Preços
O preço do Sonnet 4.5 começa em US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída.

De modelos a fluxos de trabalho: Tornando os LLMs práticos com o Zencoder
Agora que você conhece os 6 melhores LLMs para codificação, a próxima pergunta é como colocá-los em prática no seu desenvolvimento diário. Mesmo os modelos mais avançados ainda exigem um sistema adequado para se integrar às suas ferramentas, automatizar fluxos de trabalho e fornecer resultados consistentes em grandes projetos.
É aí que entra o Zencoder! Ele permite que você conecte seu modelo (ou modelos) favorito a um agente de codificação de nível de produção que simplifica os fluxos de trabalho, lida com a integração e garante a confiabilidade em escala.
O que é o Zencoder

O Zencoder é um agente de codificação alimentado por IA que aprimora o ciclo de vida de desenvolvimento de software (SDLC), melhorando a produtividade, a precisão e a criatividade por meio de soluções avançadas de inteligência artificial. Com sua tecnologia Repo Grokking™, o Zencoder analisa minuciosamente toda a sua base de código, descobrindo padrões estruturais, lógica arquitetônica e implementações personalizadas.
Além disso, com a compatibilidade universal de ferramentas, você pode trazer sua própria CLI, incluindo Claude Code, OpenAI Codex ou GoogleGemini, diretamente para o seu IDE com contexto completo. Ele também oferece inteligência multi-repo, permitindo que o Zencoder compreenda bases de código em escala empresarial, conexões de serviço e propagação de dependência.
Veja a seguir alguns dos principais recursos do Zencoder:
1️⃣ Integrações - Integra-se perfeitamente a mais de 20 ambientes de desenvolvimento, simplificando todo o seu ciclo de vida de desenvolvimento. Isso faz do Zencoder o único agente de codificação de IA que oferece esse amplo nível de integração.
4️⃣ All-in-One AI Coding Assistant - Acelere seu fluxo de trabalho de desenvolvimento com uma solução de IA integrada que oferece conclusão inteligente de código, geração automática de código e revisões de código em tempo real.
- Conclusão de código - As sugestões inteligentes de código mantêm seu ritmo com conclusões precisas e sensíveis ao contexto que reduzem os erros e aumentam a produtividade.
- Geração de código - produz código limpo, consistente e pronto para produção, adaptado às necessidades do seu projeto, perfeitamente alinhado com seus padrões de codificação.
- Code Review Agent - A revisão contínua do código garante que cada linha atenda às práticas recomendadas, detecte possíveis bugs e melhore a segurança por meio de feedback preciso e acionável.
- Chat Assistant - Receba respostas instantâneas e confiáveis e suporte de codificação personalizado. Mantenha-se produtivo com recomendações inteligentes que mantêm seu fluxo de trabalho tranquilo e eficiente.
3️⃣ Security treble - O Zencoder é o único agente de codificação de IA com certificação SOC 2 Tipo II, ISO 27001 e ISO 42001.
5️⃣ Zentester - O Zentester usa IA para automatizar testes em todos os níveis, para que sua equipe possa detectar bugs antecipadamente e enviar códigos de alta qualidade mais rapidamente. Basta descrever o que você deseja testar em inglês simples, e o Zentester cuida do resto, adaptando-se à medida que seu código evolui.
Veja o Zentester em ação:
Aqui está o que ele faz:
- Nossos agentes inteligentes entendem seu aplicativo e interagem naturalmente nas camadas de UI, API e banco de dados.
- À medida que seu código muda, o Zentester adapta automaticamente seus testes, eliminando a necessidade de reescrita constante.
- De funções de unidade a fluxos de usuário de ponta a ponta, cada camada do seu aplicativo é testada minuciosamente em escala.
- A IA do Zentester identifica caminhos de código arriscados, revela casos de borda ocultos e cria testes com base em como os usuários reais interagem com seu aplicativo.
6️⃣ Zen Agents - Os Zen Agents são companheiros de equipe de IA totalmente personalizáveis que entendem seu código, integram-se perfeitamente às suas ferramentas existentes e podem ser implantados em segundos.

Com os Zen Agents, você pode:
- Construir de forma mais inteligente - Crie agentes especializados para tarefas como revisões de solicitações pull, testes ou refatoração, adaptados à sua arquitetura e estruturas.
- Integrar rapidamente - Conecte-se a ferramentas como Jira, GitHub e Stripe em minutos usando nossa interface MCP sem código, para que seus agentes sejam executados diretamente em seus fluxos de trabalho existentes.
- Implementeinstantaneamente - Implemente agentes em toda a sua organização com um clique, com atualizações automáticas e acesso compartilhado para manter as equipes alinhadas e a experiência dimensionável.
- Explore o mercado - Navegue por uma biblioteca crescente de agentes pré-construídos de código aberto, prontos para serem inseridos em seu fluxo de trabalho, ou contribua com o seu próprio agente para ajudar a comunidade a avançar mais rapidamente.
Comece a usar o Zencoder gratuitamente e transforme qualquer LLM em um agente de codificação pronto para produção!



