
Große Sprachmodelle (LLMs) werden schnell zu einem wesentlichen Bestandteil der modernen Softwareentwicklung. Jüngste Untersuchungen zeigen, dass mehr als die Hälfte der leitenden Entwickler (53 %) glauben, dass diese Tools bereits effektiver codieren können als die meisten Menschen. Diese Modelle werden täglich eingesetzt, um knifflige Fehler zu beheben, sauberere Funktionen zu generieren und Code zu überprüfen, was den Entwicklern viele Stunden Arbeit erspart. Da jedoch in rasantem Tempo neue LLMs auf den Markt kommen, ist es nicht immer leicht zu erkennen, welche sich lohnen, übernommen zu werden. Deshalb haben wir eine Liste der 6 besten LLMs für die Programmierung erstellt, die Ihnen helfen können, intelligenter zu programmieren, Zeit zu sparen und Ihre Produktivität zu steigern.

6 beste LLMs für Coding, die Sie 2026 in Betracht ziehen sollten
Bevor wir tiefer in unsere Top-Picks eintauchen, erfahren Sie hier, was Sie erwartet:
|
Modell |
Am besten für |
Genauigkeit |
Schlussfolgerungen |
Kontext-Fenster |
Kosten |
Ökosystem-Unterstützung |
Open-Source-Verfügbarkeit |
|
GPT-5 (OpenAI) |
Beste Gesamtleistung |
74,9% (SWE-Bench) / 88% (Aider Polyglot) |
Mehrstufiges Reasoning, kollaborative Workflows |
400K Token (272K Eingabe + 128K Ausgabe) |
Kostenlos + kostenpflichtige Tarife ab $20/mo |
Sehr stark (Plugins, Tools, Entwicklerintegration) |
Geschlossen |
|
Claude 4 Sonnet (Anthropisch) |
Komplexe Fehlersuche |
72,7% (SWE-Bench verifiziert) |
Erweiterte Fehlersuche, Planung, Befehlsverfolgung |
128K Token |
Kostenlos + kostenpflichtige Tarife ab $17/mo |
Wachsendes Ökosystem mit Tool-Integrationen |
Geschlossen |
|
Gemini 2.5 Pro (Google) |
Große Codebases & Full Stack |
SWE-Bench Verifiziert: ~63,8% (Agentencodierung); LiveCodeBench: ~70,4%; Aider Polyglot: ~74,0% |
Kontrolliertes Reasoning ("Deep Think"), mehrstufige Arbeitsabläufe |
1.000.000 Token |
$1,25 pro Million Input + $10 pro Million Output |
Stark (Google-Tool & API-Integration) |
Geschlossen |
|
DeepSeek V3.1 / R1 |
Bester Wert (Open-Source) |
Entspricht älteren OpenAI-Modellen, nähert sich Gemini in der Argumentation an |
RL-abgestimmte Logik & Selbstreflexion |
128K Token |
Eingabe: $0.07-0.56/M, Ausgabe: $1.68-2.19/M |
Mittel (Open-Source-Übernahme, Flexibilität für Entwickler) |
Offen (MIT-Lizenz) |
|
Llama 4 (Meta: Scout / Maverick) |
Open-Source (großer Kontext) |
Starke Codierungs- und Argumentationsleistung in offenen Modell-Benchmarks |
Gutes Schritt-für-Schritt-Reasoning (weniger fortgeschritten als GPT-5/Claude) |
Bis zu 10M Token (Scout) |
$0.15-0.50/M Eingabe, $0.50-0.85/M Ausgabe |
Wachsendes Open-Source-Ökosystem, Entwickler-Tools |
Offene Gewichte |
|
Claude Sonnet 4.5 (Anthropisch) |
Kollaboratives Debugging & Aufgaben mit langem Kontext |
Geschätzte ~75-77% (SWE-Bench-Klasse) |
Hybrides agentenbasiertes Denken, autonome Werkzeugnutzung und Planung |
200K Token |
$3/M Eingabe + $15/M Ausgabe |
Erweiterung des anthropischen Ökosystems mit agentenbasierten Toolchains |
Geschlossen |
1. Beste Gesamtleistung: OpenAIs GPT-5
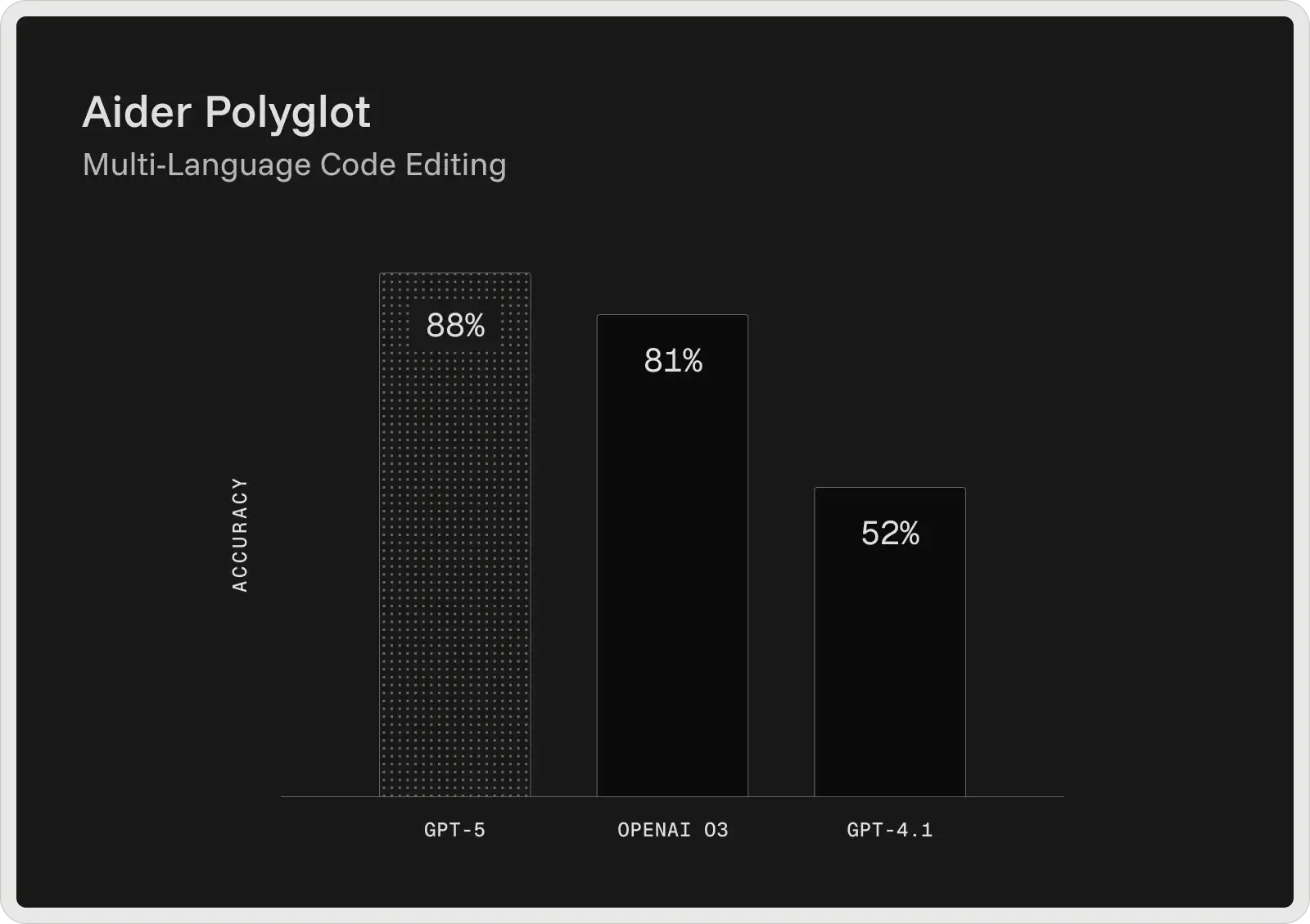
Das GPT-5 von OpenAI ist derzeit das stärkste Codierungsmodell in seiner Reihe und liefert Spitzenergebnisse in weit verbreiteten Entwickler-Benchmarks. Im SWE-Bench Verified erreicht es eine Genauigkeit von 74,9 % und im Aider Polyglot 88 %, womit die Fehlerquote im Vergleich zu früheren Modellen wie GPT-4.1 und o3 reduziert wird. GPT-5 ist als kollaborativer Programmierassistent konzipiert und kann Code generieren und bearbeiten, Fehler beheben und komplexe Fragen zu großen Codebasen konsistent beantworten.
Er liefert Erklärungen vor und zwischen den Schritten, folgt zuverlässig detaillierten Anweisungen und kann mehrstufige Codierungsaufgaben durchlaufen, ohne den Kontext zu verlieren. In internen Tests wurde es auch für die Frontend-Entwicklung bevorzugt, wobei die Entwickler in etwa 70 % der Fälle seine Ergebnisse denen von o3 vorzogen.
Schlüssel-Fähigkeiten:
- Kontextfenster mit 400K Token - Verarbeitet 272K Eingabe- und 128K Ausgabe-Token und ermöglicht so die Analyse von Repositorys, die Aufnahme von Dokumentationen und die Auswertung mehrerer Dateien.
- Erweiterte Fehlererkennung & Debugging - Identifiziert tief verborgene Probleme in großen Codebasen und bietet validierte Korrekturen mit klaren Begründungen.
- Toolintegration und -verkettung - Ruft externe Tools zuverlässig auf und unterstützt sequentielle und parallele Workflows mit weniger Fehlern.
- Anweisungstreue - Hält sich genau an detaillierte Entwickleranweisungen, selbst bei mehrstufigen oder stark eingeschränkten Aufgaben.
- Kollaborative Workflows - Gemeinsame Nutzung von Plänen, Zwischenschritten und Fortschrittsaktualisierungen während lang andauernder Codierungssitzungen.
- Long-Context-Reasoning - Bewahrt die Kohärenz über große Projekte hinweg, indem Abhängigkeiten und Logik über Hunderttausende von Token hinweg beibehalten werden.
- Zuverlässige Abfrage von Inhalten - Starke Leistung bei Benchmarks für die Abfrage von Inhalten mit langem Kontext (z. B. OpenAI-MRCR, BrowseComp), die es ermöglicht, Informationen zu finden und zu nutzen, die in sehr großen Eingaben verborgen sind.
Vor- und Nachteile:
🟢 Vorteile:
- Bewältigt längere Codierungsaufgaben und große Codebasen effektiver.
- Befolgt detaillierte Anweisungen mit höherer Genauigkeit.
- Fängt subtile Fehler auf, die andere Modelle oft übersehen.
- Produziert sauberere, weniger "halluzinierte" Antworten in einigen Fällen.
🔴 Nachteile:
- Schwierigkeiten bei der vollständigen Umsetzung komplexer, mehrstufiger Pläne.
- Halluziniert manchmal oder lässt den Code unvollständig.
- Langsame Reaktionszeit und inkonsistente Ausgabequalität.
- Der generierte Code kann zu selbstbewusst, aber anfällig sein.
Preisgestaltung
OpenAIs GPT-5 bietet einen kostenlosen Plan und 2 kostenpflichtige Pläne ab $20 pro Monat.
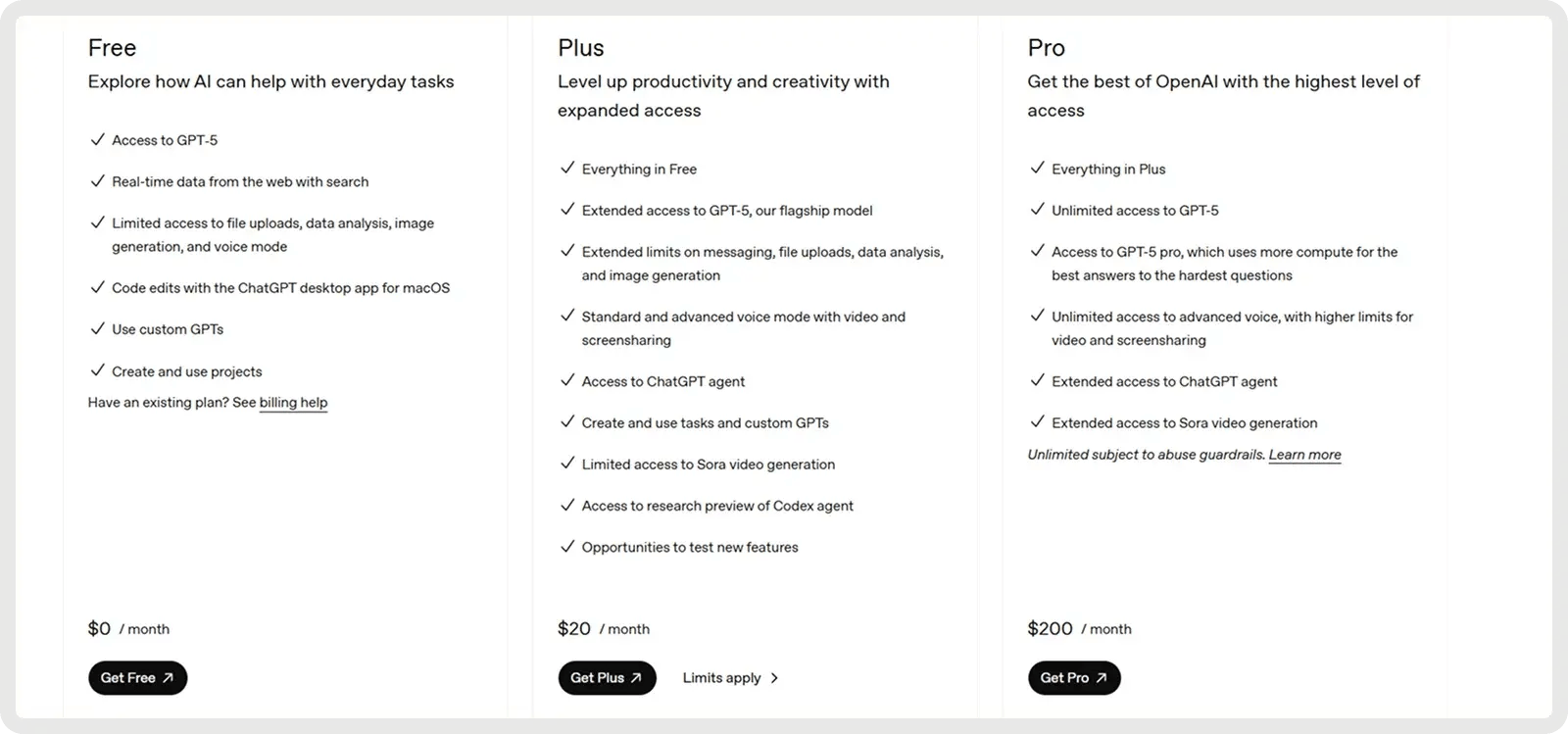
2. Am besten für komplexes Debugging: Anthropic Claude 4 (Sonnet 4)
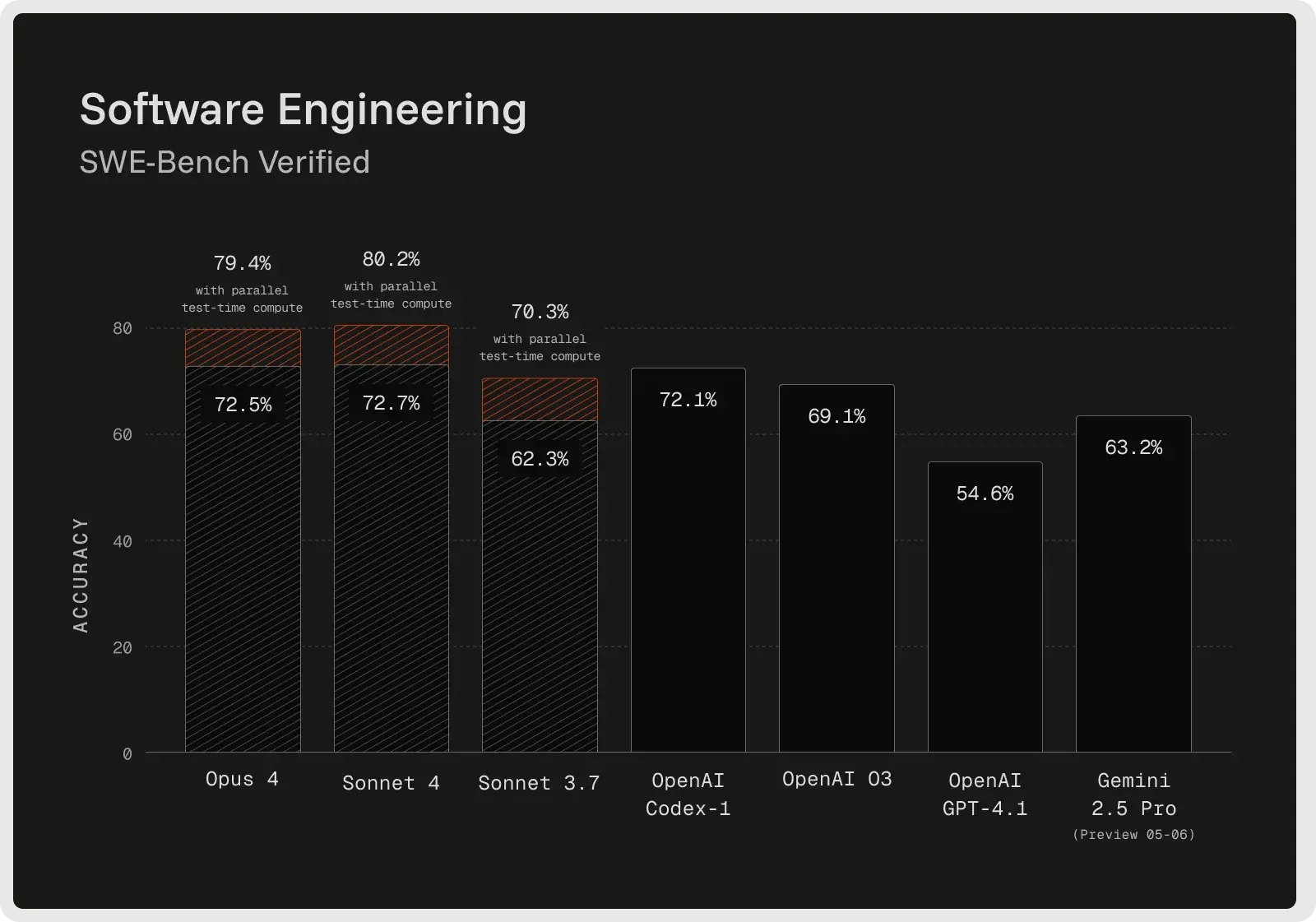
Claude Sonnet 4 wurde für fortgeschrittenes Denken entwickelt und ist besonders gut für komplexes Debugging und Code-Review geeignet. Das Modell skizziert oft einen Plan, bevor es Änderungen vornimmt, was die Klarheit verbessert und dazu beiträgt, Probleme früher im Prozess zu erkennen. Beim SWE-Bench Verified Benchmark erreichte eseine Genauigkeit von 72,7 % bei realen Fehlerbehebungen, was einen neuen Rekord darstellt und die meisten Wettbewerber übertrifft. Sein erweiterter Denkmodus ermöglicht die Verarbeitung von bis zu 128K Token, wodurch große Codebasen und unterstützende Dokumente verarbeitet werden können und Halluzinationen durch klärende Fragen reduziert werden. Die Entwickler berichten von weniger Fehlern, zuverlässigerem Umgang mit mehrdeutigen Anfragen und sichereren inkrementellen Korrekturen im Vergleich zu One-Shot-Ansätzen.
Hauptfunktionen:
- Entwicklung über den gesamten Lebenszyklus - Unterstützt den gesamten Prozess von der Planung und dem Design bis hin zum Refactoring, Debugging und der langfristigen Wartung.
- Befolgung von Anweisungen und Verwendung von Tools - Auswahl und Integration externer Tools (z. B. Datei-APIs, Codeausführung) in Arbeitsabläufe nach Bedarf.
- Fehlererkennung & Debugging - Identifiziert, erklärt und behebt Fehler mit einer klaren Begründung für Codeänderungen.
- Refactoring & Codetransformation - Führt umfangreiche Umstrukturierungen in Dateien oder ganzen Codebases durch.
- Präzise Generierung und Planung - Erzeugt sauberen, strukturierten Code, der mit dem Design und den Projektzielen übereinstimmt.
- Langes Context Reasoning - Erhält die Kohärenz über erweiterte Kontexte für große Codebases oder lange Dokumente aufrecht.
- Zuverlässige Einhaltung der Logik - Vermeidet spröde Abkürzungen und folgt der beabsichtigten Logik mit größerer Konsistenz.
Pro und Kontra:
🟢 Vorteile:
- Stark beim Erstellen und Abschließen größerer Codierungsaufgaben.
- Befolgt die Anweisungen zuverlässiger als frühere Versionen.
- Ausgewogenes Verhältnis zwischen Kosten und Leistung im Vergleich zu Opus.
- Liefert klare, gut strukturierte Codeausgaben.
🔴 Nachteile:
- Kann einfache Anfragen missverstehen oder zu viel erklären.
- Schwächer bei OCR und dokumentenlastigen Kodierungsaufgaben.
- Hat Probleme mit sehr komplexen, mehrstufigen Problemlösungen.
- Die Konsistenz der Ergebnisse kann je nach Codierungsbereich variieren.
Preisgestaltung
Claude bietet einen kostenlosen Plan und 2 kostenpflichtige Pläne ab 17$ pro Monat.
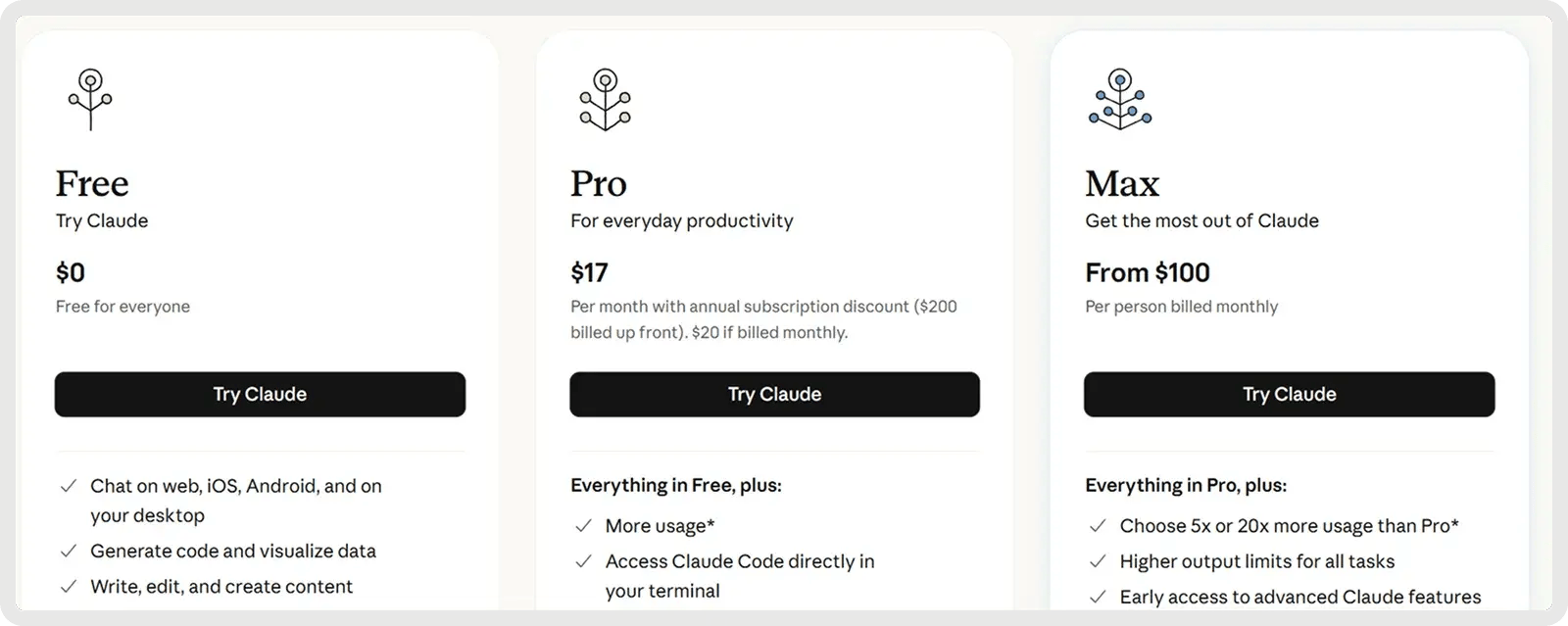
3. Am besten für große Codebases & Full Stack: Google Gemini 2.5 Pro
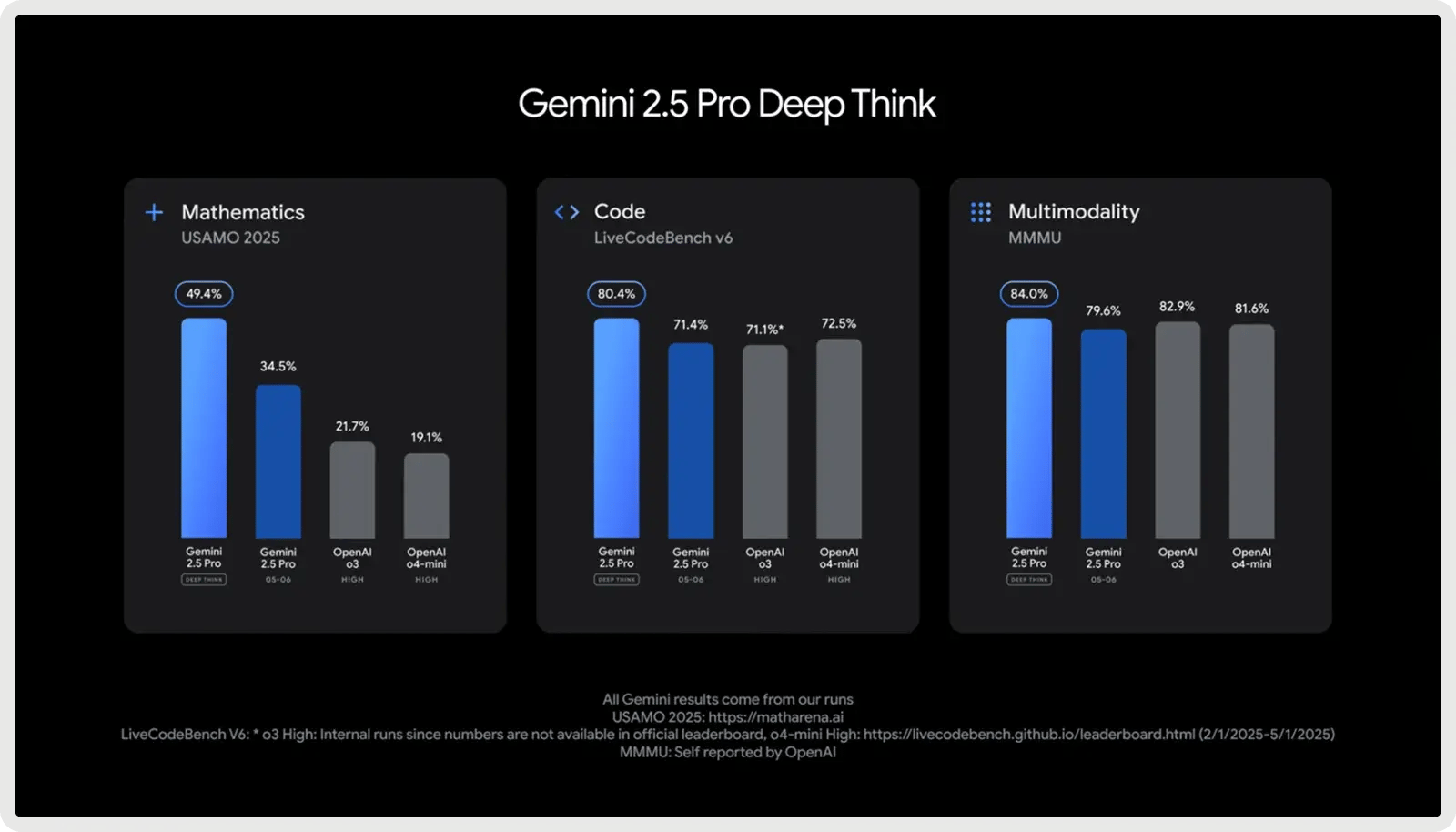
Google Gemini 2.5 Pro wurde für umfangreiche Coding-Projekte entwickelt und verfügt über ein Kontextfenster mit 1.000.000 Token, das es ermöglicht, ganze Repositories, Testsuiten und Migrationsskripte in einem einzigen Durchgang zu bearbeiten. Die Software ist für die Softwareentwicklung optimiert und eignet sich hervorragend zum Generieren, Debuggen und Refactoring von Code über mehrere Dateien und Frameworks hinweg. Es unterstützt komplexe Codierungsworkflows, von der Handhabung von Abhängigkeiten zwischen mehreren Dateien bis hin zu Datenbankabfragen und API-Integrationen. Mit schnellen Antworten und Full-Stack-Bewusstsein hilft es Entwicklern, Code über Frontend-, Backend- und Datenschichten hinweg nahtlos zu schreiben, zu analysieren und zu integrieren.
Wichtigste Funktionen:
- Codegenerierung - Erstellt neue Funktionen, Module oder ganze Anwendungen anhand von Eingabeaufforderungen oder Spezifikationen.
- Codebearbeitung - Führt gezielte Korrekturen, Verbesserungen oder Refactoring direkt in bestehenden Codebases durch.
- Mehrstufiges Reasoning - Zerlegt komplexe Programmieraufgaben in logische Schritte und führt sie zuverlässig aus.
- Frontend/UI-Entwicklung - Erstellt interaktive Webkomponenten, Layouts und Styles aus natürlicher Sprache oder Designs.
- Umgang mit großen Codebasen - Versteht und navigiert ganze Repositories mit Abhängigkeiten zu mehreren Dateien.
- MCP-Integration - Unterstützt das Model Context Protocol für die nahtlose Nutzung von Open-Source-Coding-Tools.
- Kontrollierbares Reasoning - Passt seine Problemlösungstiefe ("Denkmodus") an, um ein Gleichgewicht zwischen Genauigkeit, Geschwindigkeit und Kosten herzustellen.
Pro und Kontra:
🟢 Vorteile:
- Hervorragend bei der Erstellung vollständiger Lösungen von Grund auf.
- Beherrscht große Codebasen mit 1M-Token-Kontext.
- Starke Benchmark-Leistung bei Codierungsaufgaben.
- Deep Think verbessert die Argumentation bei komplexen Problemen.
🔴 Nachteile:
- Schwächer bei Debugging und Codekorrekturen.
- Manchmal halluziniert es oder ändert Code ungefragt.
- Ausführliche Ausgaben und Formatinkonsistenzen.
- Gemischte Zuverlässigkeit im Vergleich zu früheren Versionen.
Preisgestaltung
Google Gemini 2.5 Pro bietet einen kostenlosen Plan und einen kostenpflichtigen Plan ab 1,25 $ pro Million Eingabe-Token und 10 $ pro Million Ausgabe-Token. Zusätzliche Tarife gelten für Prompts, die 200k Token überschreiten, sowie für optionale Caching- und Grounding-Gebühren.
4. Bester Wert (Open-Source): DeepSeek V3.1/R1

Die Modelle V3.1 und R1 von DeepSeek bieten ein gutes Preis-Leistungs-Verhältnis für Entwickler, die sowohl auf Erschwinglichkeit als auch auf Open-Source-Flexibilität Wert legen. Diese Mixture-of-Experts-Modelle, die unter der MIT-Lizenz lizenziert sind, wurden speziell für Mathematik- und Codierungsaufgaben optimiert. Das R1-Modell wurde mit Reinforcement Learning für fortgeschrittenes Denken und Logik optimiert und zeigt eine Leistung, die der älterer OpenAI-Modelle entspricht oder diese übertrifft und bei komplexen Denk-Benchmarks an den Gemini 2.5 Pro heranreicht.
Schlüssel-Fähigkeiten:
- Mixture-of-Experts-Effizienz - Aktiviert nur eine Teilmenge von Experten pro Anfrage und bietet so eine hohe Kapazität, während die Inferenzkosten niedriger sind als bei dichten Modellen.
- Reinforcement Learning for Reasoning (R1) - Feinabstimmung mit RL zur Verbesserung von Chain-of-Thought-Reasoning, logischen Schlussfolgerungen und schrittweiser Genauigkeit.
- Fortgeschrittene Mathematik- und Logikleistung - Starke Ergebnisse bei Benchmarks wie MATH und AIME, wodurch es besonders gut im symbolischen Denken und Problemlösen ist.
- Selbstüberprüfung und Reflexion - Generiert interne Argumentationsketten und kann Antworten selbst überprüfen, was die Zuverlässigkeit bei komplexen, mehrstufigen Aufgaben verbessert.
- Open-Source & MIT lizenziert - Eine völlig freie Lizenz ermöglicht Einsichtnahme, Modifikation und uneingeschränkte kommerzielle Nutzung, im Gegensatz zu den meisten proprietären LLMs.
- Skalierbarkeit und Einsatzoptionen - Unterstützt Quantisierung und destillierte Varianten, die den Einsatz auf kleinerer Hardware mit minimalem Leistungsverlust ermöglichen.
- Mehrsprachige Unterstützung - Trainiert für mehrere Sprachen (einschließlich Englisch und Chinesisch), was eine breitere Anwendbarkeit für globale Entwickler ermöglicht.
Vor- und Nachteile:
🟢 Vorteile:
- Erzeugt vollständige, funktionale Lösungen mit hoher Zuverlässigkeit.
- Unterstützt große Codebasen mit einem erweiterten 128k-Kontext.
- Der "Think"-Modus verbessert die Argumentation bei komplexen Programmieraufgaben.
- Offenes Modell mit geringeren Betriebskosten.
🔴 Nachteile:
- Begrenzte Präzision bei der Befolgung detaillierter Codierungsanweisungen.
- Ausführliche Ausgaben, insbesondere im Argumentationsmodus.
- Bleibt bei der Codequalität hinter führenden Modellen zurück.
- Potenzielle Sicherheits- und Anpassungsrisiken im generierten Code.
Preisgestaltung
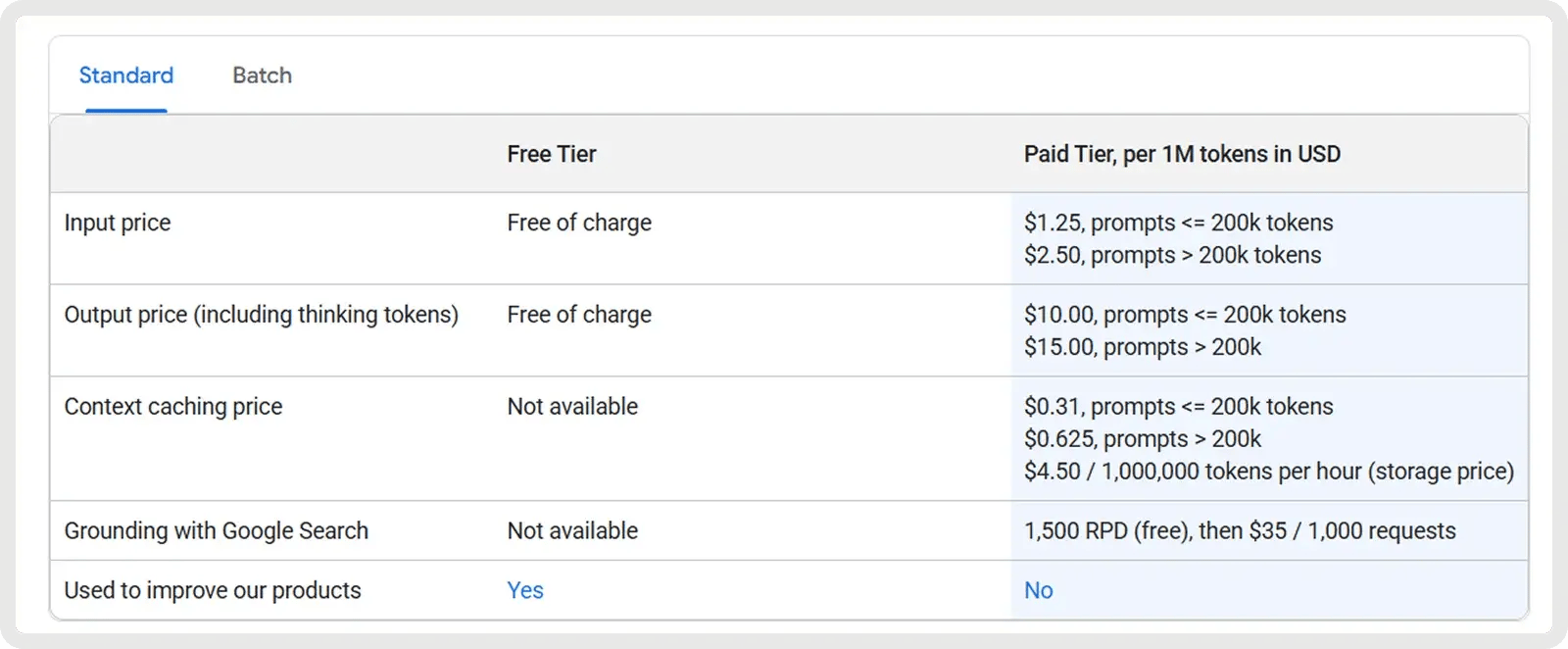
V3.1 ist ein kosteneffizientes, universell einsetzbares Modell mit Eingabe-Token zu 0,07 $ pro 1 Million (Cache-Treffer) bzw. 0,56 $ pro 1 Million (Cache-Fehler) und Ausgabe-Token zu 1,68 $ pro 1 Million. Dies macht es für Anwendungsfälle mit hohem Volumen sehr attraktiv, insbesondere wenn Caching effektiv ist.
R1, das als Premium-Reasoning-Modell positioniert ist, kostet etwa 0,14 $ pro Million Input-Token und etwa 2,19 $ pro Million Output-Token.
5. Beste Open-Source-Lösung (großer Kontext): Meta Llama 4
Metas neueste Open-Source-Modelle, Llama 4 Scout und Maverick (veröffentlicht im April 2025), erweitern die Kontextlänge drastisch, wobei Scout (17B Parameter) bis zu 10 Millionen Token unterstützt und multimodale Eingaben verarbeitet. Scout zeigt signifikante Verbesserungen bei der Codierung, indem es bei Benchmarks wie MBPP eine höhere Genauigkeit erreicht und im Vergleich zu Llama 3 eine bessere Handhabung langer, mehrere Dateien umfassender Programmieraufgaben zeigt. Entwickler können mit Scout komplexe Codierungsaufgaben wie Refactoring mehrerer Dateien, Verfolgung von Abhängigkeiten oder End-to-End-Systemanalysen bewältigen, ohne dass das Modell den früheren Kontext "vergisst". Da es Open-Source und kommerziell nutzbar ist, können Teams es für ihre eigenen Arbeitsabläufe anpassen und es sicher auf lokaler Hardware ausführen.
Hauptfunktionen:
- Codegenerierung - Erzeugt präzisen, funktionalen Code für ein breites Spektrum von Programmieraufgaben.
- Interaktive Codierung - Unterstützt Codevervollständigung, -bearbeitung und -debugging in Echtzeit.
- Funktionsaufrufe - Generiert strukturierte Ausgaben (z. B. JSON) zum Aufrufen von APIs oder zur Integration mit externen Tools.
- Handhabung von umfangreichem Code - Verwaltung ganzer Repositories oder Projekte mit mehreren Dateien, ohne den Kontext zu verlieren, dank eines Fensters mit 10 Millionen Token.
- Befolgung von Anweisungen - Passt sich präzise an kodierungsspezifische Aufforderungen für Aufgaben wie Bugfixes, Refactoring oder Algorithmenentwurf an.
- Effiziente Bereitstellung - Läuft effektiv auf lokaler Hardware und macht umfangreiche Programmierunterstützung leichter zugänglich.
- Code Reasoning - Versteht Abhängigkeiten und Semantik innerhalb von Codebases und unterstützt so tiefere Analysen und Einblicke auf Systemebene.
Pro und Kontra:
🟢 Vorteile:
- Schnelle Inferenz, praktisch für lokale Codierung.
- Konkurrenzfähige Kodierungsergebnisse unter den offenen Modellen.
- Kann mit sehr langen Code-/Kontextfenstern umgehen.
- Offenes Gewicht und anpassbar für den privaten Gebrauch.
🔴 Nachteile:
- Bleibt bei der Codiergenauigkeit hinter Topmodellen (GPT-5, Claude) zurück.
- Inkonsistent oder fehlerhaft bei anspruchsvollen Kodierungsaufgaben.
- Der Ausgabestil kann trocken oder synthetisch wirken.
- Begrenztes Feedback zur Akzeptanz.
Preisgestaltung
Die Preise für Llama 4 liegen derzeit bei etwa $0,15/M Eingabe- und $0,50/M Ausgabe-Token für Scout und $0,22-0,27/M Eingabe- und $0,85/M Ausgabe-Token für Maverick, wobei sie je nach Anbieter leicht variieren.
6. Am besten geeignet für kollaboratives Debugging und Aufgaben mit langen Kontexten: Claude Sonnet 4.5
Claude Sonnet 4.5 ist das neueste und leistungsfähigste hybride Argumentationsmodell von Anthropic, das Sonnet 4 durch schärfere Intelligenz, schnellere Codegenerierung und verbesserte Koordination der Agenten erweitert. Es verfügt über ein Kontextfenster mit 200.000 Token, eine höhere Genauigkeit bei der Verwendung von Tools und ein verfeinertes Domänenwissen in den Bereichen Programmierung, Finanzen und Cybersicherheit. Optimiert für erweiterte Argumentation und Zusammenarbeit in großem Maßstab, eignet sie sich hervorragend für die Verwaltung komplexer Codierungsprojekte, autonomer Agenten und langwieriger Analyseaufgaben.
Hauptfunktionen:
- Durchgängige Codegenerierung - Übernimmt den gesamten Lebenszyklus der Softwareentwicklung, von der Planung und Implementierung bis hin zum Debugging, Refactoring und zur Wartung.
- Erweiterte Argumentation - Führt mehrstufige logische Analysen durch und folgt komplexen Anweisungen, um anspruchsvolle Programmieraufgaben zu lösen.
- Automatische Fehlerkorrektur - Erkennt, erklärt und behebt Codeprobleme in Echtzeit, um die Zuverlässigkeit zu erhöhen und den Debugging-Aufwand zu reduzieren.
- Erweitertes Kontextfenster - Unterstützt bis zu 64K Token, um große Codebasen, Designdokumente und projektweite Abhängigkeiten zu verstehen, ohne den Kontext zu verlieren.
- Autonome Tool-Integration - Auswahl und Einsatz geeigneter Entwicklungstools wie Compiler, Interpreter und Versionskontrollsysteme für optimierte Arbeitsabläufe.
- Proaktive Cybersicherheit - Identifiziert, entschärft und flickt Schwachstellen selbstständig, um sichere und widerstandsfähige Codebasen zu erhalten.
- Dauerhafter Agentenbetrieb - Führt langwierige Codierungsaufgaben aus und verwaltet mehrstufige Arbeitsabläufe kontinuierlich über Sitzungen hinweg.
Pro und Kontra:
🟢 Vorteile:
- Starke Argumentation und Codiergenauigkeit über Aufgaben hinweg.
- Ausgezeichnete Kontextspeicherung und Bewusstsein für mehrere Dateien.
- Effiziente Nutzung von Tools und strukturierte Problemlösung.
- Fähig zu längeren, autonomeren Kodierungssitzungen.
🔴 Nachteile:
- Langsamere Reaktionen bei tiefgreifenden Überlegungen oder Planungen.
- Gelegentliches Abdriften von Anweisungen und sachliche Fehler.
- Immer noch begrenztes Kontextfenster für sehr große Projekte.
- Kämpft mit interaktiven Umgebungen
Preisgestaltung
Die Preise für Sonnet 4.5 beginnen bei $3 pro Million Input-Token und $15 pro Million Output-Token.

Von Modellen zu Arbeitsabläufen: LLMs praktisch machen mit Zencoder
Jetzt, da Sie die 6 besten LLMs für die Codierung kennen, stellt sich die nächste Frage, wie Sie sie in Ihrer täglichen Entwicklung einsetzen können. Selbst die fortschrittlichsten Modelle erfordern immer noch ein geeignetes System zur Integration mit Ihren Tools, zur Automatisierung von Arbeitsabläufen und zur Bereitstellung konsistenter Ergebnisse über große Projekte hinweg.
Und genau hier kommt Zencoder ins Spiel! Mit Zencoder können Sie Ihr Lieblingsmodell (oder Ihre Lieblingsmodelle) in einen produktionsreifen Coding Agent einbinden, der Arbeitsabläufe optimiert, die Integration übernimmt und die Zuverlässigkeit in großem Umfang gewährleistet.
Was ist Zencoder?

Zencoder ist ein KI-gestützter Coding Agent, der den Lebenszyklus der Softwareentwicklung (SDLC) verbessert, indem er die Produktivität, Genauigkeit und Kreativität durch fortschrittliche Lösungen der künstlichen Intelligenz steigert. Mit seiner Repo Grokking™-Technologie analysiert Zencoder gründlich Ihre gesamte Codebasis und deckt strukturelle Muster, architektonische Logik und benutzerdefinierte Implementierungen auf.
Darüber hinaus können Sie dank der universellen Toolkompatibilität Ihre eigene CLI, einschließlich Claude Code, OpenAI Codex oder GoogleGemini, direkt in Ihre IDE mit vollem Kontext einbringen. Es bietet auch Multi-Repo-Intelligenz, die Zencoder in die Lage versetzt, Codebasen im Unternehmensmaßstab, Serviceverbindungen und die Ausbreitung von Abhängigkeiten zu verstehen.
Hier sind einige der wichtigsten Funktionen von Zencoder:
1️⃣ Integrationen - Nahtlose Integration mit über 20 Entwicklerumgebungen, die Ihren gesamten Entwicklungszyklus vereinfachen. Damit ist Zencoder der einzige KI-Codierungsagent, der ein so umfassendes Maß an Integration bietet.
4️⃣ All-in-One AI Coding Assistant - Beschleunigen Sie Ihren Entwicklungs-Workflow mit einer integrierten AI-Lösung, die intelligente Code-Vervollständigung, automatische Code-Generierung und Code-Reviews in Echtzeit bietet.
- Code-Vervollständigung - Intelligente Code-Vorschläge sorgen dafür, dass Sie mit kontextabhängigen, präzisen Vervollständigungen, die Fehler reduzieren und die Produktivität steigern, in Schwung bleiben.
- Codegenerierung - Erzeugt sauberen, konsistenten und produktionsreifen Code, der auf die Anforderungen Ihres Projekts zugeschnitten ist und perfekt mit Ihren Codierungsstandards übereinstimmt.
- Code Review Agent - Kontinuierliche Codeüberprüfung stellt sicher, dass jede Zeile den Best Practices entspricht, fängt potenzielle Fehler ab und verbessert die Sicherheit durch präzises, umsetzbares Feedback.
- Chat-Assistent - Erhalten Sie sofortige, zuverlässige Antworten und personalisierte Unterstützung bei der Programmierung. Bleiben Sie produktiv mit intelligenten Empfehlungen, die Ihren Arbeitsablauf reibungslos und effizient gestalten.
3️⃣ Sicherheitszertifikat - Zencoder ist der einzige KI-Codierungsagent mit SOC 2 Typ II, ISO 27001 & ISO 42001 Zertifizierung.
5️⃣ Zentester - Zentester nutzt KI, um das Testen auf jeder Ebene zu automatisieren, so dass Ihr Team Bugs frühzeitig erkennen und qualitativ hochwertigen Code schneller ausliefern kann. Beschreiben Sie einfach in einfachem Englisch, was Sie testen möchten, und Zentester kümmert sich um den Rest und passt sich an die Entwicklung Ihres Codes an.
Sehen Sie Zentester in Aktion:
So funktioniert es:
- Unsere intelligenten Agenten verstehen Ihre Anwendung und interagieren auf natürliche Weise über UI-, API- und Datenbankschichten hinweg.
- Wenn sich Ihr Code ändert, passt Zentester Ihre Tests automatisch an, so dass sie nicht ständig neu geschrieben werden müssen.
- Von Unit-Funktionen bis hin zu End-to-End-Benutzerströmen wird jede Schicht Ihrer Anwendung gründlich und in großem Umfang getestet.
- Die KI von Zentester identifiziert riskante Codepfade, deckt versteckte Randfälle auf und erstellt Tests auf der Grundlage der Interaktion echter Benutzer mit Ihrer Anwendung.
6️⃣ Zen Agents - Zen Agents sind vollständig anpassbare KI-Teammates, die Ihren Code verstehen, sich nahtlos in Ihre bestehenden Tools integrieren und in Sekundenschnelle implementiert werden können.

Mit Zen Agents können Sie:
- Intelligenter bauen - Erstellen Sie spezialisierte Agenten für Aufgaben wie Pull-Reviews, Tests oder Refactoring, die auf Ihre Architektur und Frameworks zugeschnitten sind.
- Schnelles Integrieren - Verbinden Sie sich mit Tools wie Jira, GitHub und Stripe in wenigen Minuten über unsere no-code MCP-Schnittstelle, damit Ihre Agenten direkt in Ihren bestehenden Arbeitsabläufen laufen.
- Sofortige Bereitstellung - Stellen Sie Agenten in Ihrem Unternehmen mit einem Klick bereit, mit automatischen Aktualisierungen und gemeinsamem Zugriff, damit die Teams aufeinander abgestimmt und das Know-how skalierbar bleibt.
- Erkunden Sie den Marktplatz - Durchsuchen Sie eine wachsende Bibliothek mit vorgefertigten Open-Source-Agenten, die Sie in Ihren Workflow einfügen können, oder tragen Sie mit Ihren eigenen Agenten dazu bei, dass sich die Community schneller entwickelt.
Starten Sie kostenlos mit Zencoder und verwandeln Sie jedes LLM in einen produktionsbereiten Coding Agent!



